使用方法
別ページ
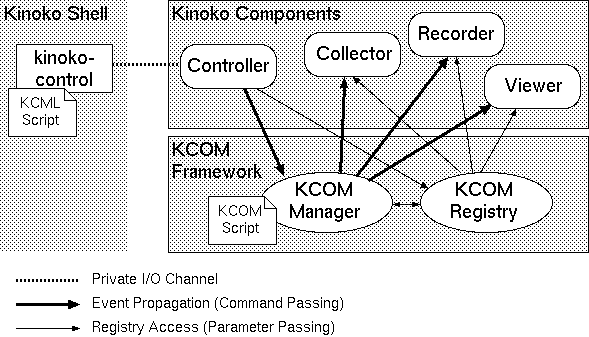
KiNOKO の構造
[TinyKinoko, SmallKinoko のみを使う場合はこの章は読み飛ばして構いません]
KCOM フレームワークとコンポーネント
コンポーネント
Kinoko のシステムは,コンポーネントと呼ばれる単機能部品の組み合わせにより構築されます.
コンポーネントには,ハードウェアをコントロールし,データを取得するもの(Collector)やデータを記憶装置に記録するもの(Recorder),データをヒストグラムなどにして画面に表示するもの(Viewer)やユーザのコントロールをシステムに通知するもの(Controller) などがあります.また,ユーザが独自のコンポーネントを作成し,それをシステムに追加することもできます.多くのコンポーネントは,独自のスクリプト言語をもっていて,その動作を実行時にカスタマイズできるようになっています.
一つのコンポーネントは,一つの UNIX プロセスとして実装されていますが,他のコンポーネントと連携して動作できるようにするために,以下の4つの特別なインターフェースを備えています.
- プロパティ
- イベントとイベントスロット
- オブジェクトのエクスポートとインポート
- グローバルレジストリ
プロパティとは,他のコンポーネントから非同期に参照できるコンポーネント内部の値です.
オブジェクトでいう内部変数に相当します.他のコンポーネントから値を読むことはできますが,変更することはできません.
イベント/イベントスロットは,コンポーネント間の同期的メッセージ交換メカニズムで,オブジェクトでいうメソッド呼び出しに相当します.すなわち,コンポーネントは,他のコンポーネントにイベントを投げることができ,イベントを受け取ったコンポーネントはそれに応じて処理を開始することができるということです.
オブジェクトのエクスポートとインポートの機能を使うことにより,コンポーネントは内部のオブジェクトを共有することができます.例えば,システムのログを記録するコンポーネントである Logger コンポーネントは,内部に通常のオブジェクトである Logger オブジェクトを持っていて,これをエクスポートしています.他のコンポーネントはこれをインポートし,別コンポーネントのオブジェクトであることを気にせずに,このロガーオブジェクトを使うことができるようになっています.
レジストリは,特定のコンポーネントに属さないパラメータを管理するためのグローバルなパラメータデータベースです.全てのコンポーネントから非同期に参照できるようになっています.
KCOM フレームワーク
これらのコンポーネント間の通信メカニズムは,全てネットワーク透過的に振舞います.すなわち,コンポーネントは複数の計算機上に分散配置でき,そしてそのことを全く意識せずに連携して動作できるということです.
ネットワーク透過的な同期・非同期コンポーネント間通信を実現するためには,コンポーネント間通信を媒介し,コンポーネントをコントロールするインフラストラクチャが必要です.これが KCOM フレームワークです.Kinoko のシステムが立ち上げられると,まずはじめに KCOM フレームワークのコアである KCOM マネージャプロセスが起動されます.続いて,マネージャプロセスはシステムで使用する全ての計算機上にサービスプロセス(broker)を走らせ,それらとの通信経路を確立します.broker は,自分の計算機上に共有メモリやメッセージキューなどのリソースを確保し,コンポーネントが通信できる環境を整えます.これらのインフラストラクチャの構築が終了すると,broker は,KCOM マネージャからの指示により,コンポーネントプロセスを起動し,準備した通信環境に接続させます.コンポーネント間の通信は,基本的に全てこれらの broker とマネージャにより仲介されます.
起動するコンポーネントの種類や数,配置する計算機などの情報はスクリプト(KcomScript)により記述されます.また,コンポーネント間共有オブジェクトの結合なども,このスクリプトに記述されます.コンポーネントのイベントやスロットは,コンポーネントどうしで直接接続することもできますが,これではコンポーネントの独立性や単機能性を損なうことになるので,通常は行ないません.そのかわり,コンポーネントイベントは全て KcomScript で取得し,コンポーネントのイベントスロットの呼び出しも KcomScript から行なうようにします.
以下は,KcomScript の例です.詳細については,KcomScript の章を参照してください.
1:
2: import KinokoController;
3: import KinokoCollector;
4: import KinokoLogger;
5:
6:
7: component KinokoController controller("localhost", "port: 10000");
8: component KinokoCollector collector("daq01");
9: component KinokoLogger logger("localhost");
10:
11:
12: assign logger.logger => controller.logger;
13: assign logger.logger => collector.logger;
14:
15:
16: on controller.start()
17: {
18: collector.start();
19: }
20:
(以下省略)
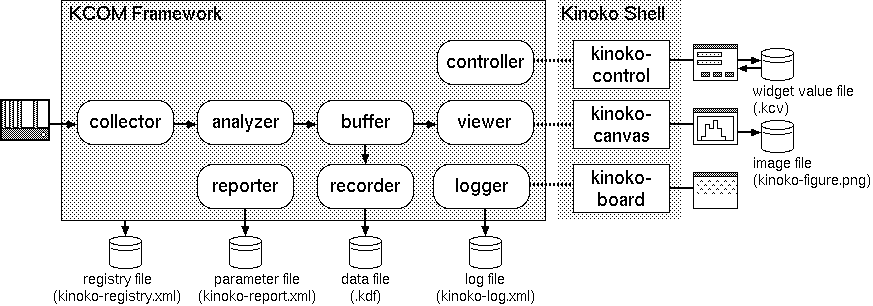
プライベート入出力チャネルと KinokoShell
コンポーネントは,KCOM フレームワークの通信チャネルとは別に,もう一つの入出力チャネルを持っています.これはプライベート入出力チャネルとよばれ,KcomScript の指定により,標準入出力や端末ウィンドウ,ネットワークポートなどに接続させることができます.上記の例では,7 行目で,controller コンポーネントのプライベート入出力チャンネルをネットワークポートの 10000 番に指定しています.
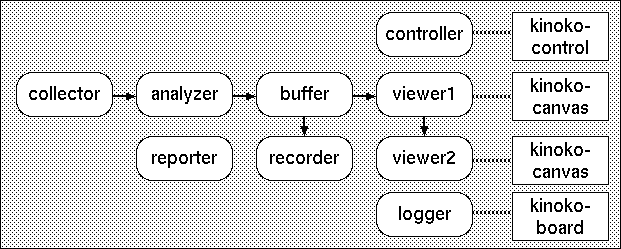
プライベート入出力チャネルは,通常,ユーザインターフェースへの接続に使われます.例えば,Controller コンポーネントはコントロールパネルへの接続にプライベート入出力チャネルを使用し,Logger はロガーウィンドウとの接続に,Viewer は描画ウィンドウとの接続に使用します.
Kinoko では,プラットフォーム独立性を保つために,そのコア部分(KinokoKernel)では,プラットフォーム依存性の強いグラフィカルユーザインターフェースを直接使用することを避けています.代わりに,プライベート入出力チャネルを使い,外部のユーザインターフェースプログラムに接続するという方法を取っています.このような,通信チャネルを介して KinokoKernel と接続し,ユーザインターフェースを担うプログラムを KinokoShell と呼びます.
現在標準で用意されている KinokoShell には以下のものがあります.
- kinoko-control
- KinokoController コンポーネントなどに接続するためのもので,入力フィールドやボタンなどを配置したコントロールパネルを表示し,ユーザの入力を伝えます.コントロールパネルのデザインは,XML を利用したスクリプト (KCML Script; Kinoko Control-panel Modeling Language) で記述されます.
- kinoko-board
- KinokoLogger コンポーネントなどに接続するためのもので,コンポーネントからテキスト描画コマンドを受け取り,それをウィンドウ内の領域に描画します.
- kinoko-canvas
- KinokoViewer コンポーネントなどに接続するためのもので,コンポーネントからグラフィクス描画コマンドを受け取り,それをウィンドウ内の領域に描画します.
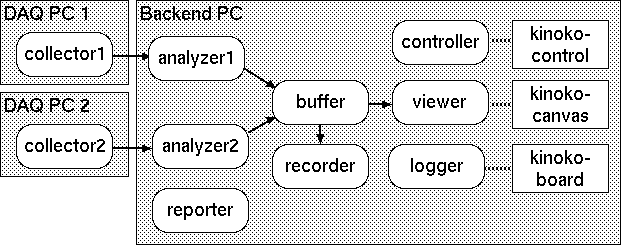
以下は,SmallKinoko におけるコンポーネントと KinokoShell の接続の構造です.
データストリーム
データストリームとデータソース
Kinoko のデータは,データパケットと呼ばれる固まりごとに転送されます.1つのパケットは,典型的には,1つのモジュールからの1回の読み出しで得られたデータになります.ただし,1つのモジュールからの読み出しを複数のパケットに分割したり,複数のモジュールからの読み出しを1つのパケットにまとめたりもできます.さらに,あるパケットをもとに,計算処理を行なって,あたらしいパケットを生成したりなどもできるようになっています.
データパケットの転送系は,データストリームと呼ばれます.データストリームの開始点となる,データパケットを生成する場所を,Kinoko ではデータソースと呼びます.ハードウェアからのデータ読み出しを行なう Collector コンポーネントは,データソースの典型的な例です.Kinoko のシステムにおいて,全てのデータソースはユニークな名前を持ち,また,システムによりユニークな識別番号(DataSourceId)が割り振られます.
Kinoko では,データストリームは自由に結合させたり分岐させたりすることができます.ストリームが結合されると,結合後のストリームには複数のデータソースからのデータパケットが混在することになります.混在するデータパケットを識別するために,全てのデータパケットの先頭には,DataSourceId が記録されています.
データストリームコンポーネントタイプ
データストリームを構成するコンポーネントは,そのストリームへの接続の形態により,以下の種類に分類されます.
- ストリームソース (KinokoCollector, KinokoReproducer など)
- ストリームシンク (KinokoRecorder, KinokoViewer など)
- ストリームパイプ (KinokoTransporter, MyDataProcessor など)
- データバッファ (KinokoBuffer のみ)
ストリームソースは,データソースをもち,データパケットを生成するコンポーネントです.ストリームシンクは,反対に,データパケットを受け取るだけで,下流側のストリームを持ちません.Recorder や Viewer などがストリームシンクの代表例です.これらはデータストリームに対してはパケットを受け取るだけで,パケットを送り出すことはしません.
ストリームパイプは,データストリームからデータパケットを受け取って,必要なら何らかの処理を行ない,下流のデータストリームにパケットを送り出すタイプのコンポーネントです.オンラインのデータ処理コンポーネントがこの例です.また,Kinoko には,なにもしないでそのまま送り出すコンポーネント KinokoTransporter があります.
データバッファは,ストリーム中では特殊なコンポーネントです.UNIX の共有メモリとメモリマネージャから構成され,その名前のとおり,ストリーム中でバッファとして機能するものです.共有メモリを使用しているため,多くの場面で効率良く動作します.バッファには以下のような用途があります.
- データフローレートの緩急を吸収する
- ストリーム下流の処理能力の変動を吸収する
- 複数のストリームからのデータを集める(ストリームを結合させる)
- 複数のストリームにデータを分配する(ストリームを分岐させる)
ストリームパイプは一つの入力ストリームと一つの出力ストリームしか持てないことに注意してください.ストリームを結合・分岐させるときは,常にバッファを使用します.以下は,2つのデータソースからのデータストリームを,バッファを介して結合させ,さらにそこで2つのデータストリームに分岐させている例です.
バッファは,ストリームに対して受動的なコンポーネントで,入って来たデータパケット全てを,何の処理も加えずに全ての出力ストリームに分配します.また,共有メモリを使用しているため,ネットワーク越しのアクセスができません.ネットワーク越しにバッファに接続したい場合は,バッファ側の計算機に Transporter コンポーネントを入れるようにしてください(このあたりの仕様は将来改善する予定です).
データストリームコンポーネントの配置と接続
データストリームコンポーネントの配置や接続も,通常のコンポーネントと同様に,KcomScript に記述して行ないます.ただし,KcomScript は汎用のコンポーネントフレームワークであるため,データストリーム構築に対する特別の機能はありません.ストリームの構築は,通常のコンポーネントのイベントスロットの呼び出しにより行ないます.
ストリームソースコンポーネントには,接続先を指定するためのスロット setSink() があります.同様に,ストリームシンクコンポーネントには,setSource() が,ストリームパイプには setSourceSink() があります.これらを接続する際には,両方向から接続先を指定する必要があります(ソース側もシンク側も setSink()/setSource() を行なう).
バッファは受動的なコンポーネントなので,バッファ自体には接続先を指定するスロットはありません.ただし,接続要求を処理するために,はじめに start() を呼んでおく必要があります.
setSink()/setSource() で全てのコンポーネントの接続先を指定したら,connect() を呼んで接続を確立します.以下は,上記の配置例のストリーム接続を行なう KcomScript の例です(詳細については KcomScript の章で解説します).
void connect()
{
buffer.start();
collector1.setSink(buffer);
collector2.setSink(buffer);
recorder.setSource(buffer);
analyzer.setSourceSink(buffer, viewer);
viewer.setSource(analyzer);
collector1.connect();
collector2.connect();
recorder.connect();
analyzer.connect();
viewer.connect();
}
システムの終了時には,disconnect() を呼んでストリームの接続を解体します.
void disconnect()
{
collector1.disconnect();
collector2.disconnect();
recorder.disconnect();
analyzer.disconnect();
viewer.disconnect();
}
コントロールパケット
データストリームを流れるものには,データパケットの他に,コントロールパケットと呼ばれる,特殊なパケットがあります.コントロールパケットは,主にランの開始や終了などを下流のコンポーネントに伝達するために使われるもので,以下の種類があります.
- RunBegin
- RunEnd
- RunSuspend
- RunResume
全てのデータソースは,ランの開始や終了の際にこれらのパケットをストリームに流します.下流のコンポーネントは,例えば RunEnd パケットを受け取ることにより,全てのデータの処理が終ったことを知ることができることになります.ストリームシンクでは,接続されているデータソースの数だけコマンドパケットを受け取ることに注意してください.例えば,2つの Collector が接続された Recorder は,2つの RunEnd パケットを受け取るまで処理を終了できないことになります.
ストリームデータフォーマット
データセクションとセクションタイプ
データストリームを流れるデータは,データセクションと呼ばれる単位に構造化されています.
特に指定せずにハードウェアからのデータ読み出しを行なう場合には,1つのモジュールが1つのセクションに対応します.このとき,1つのデータパケットには1つのモジュールからの1回の読み出し分のデータが記録されることになるため,1つのデータパケットは1つのデータセクションのデータを1つを保持することになります.データセクションに対応するデータをセクションデータと呼びます.
全てのデータセクションは,データソース内でユニークなセクション名を持っています.また,システムによって,SectionId と呼ばれる識別番号が割り振られます.全てのセクションデータには,この SectionId が記録され,どのデータセクションのデータであるかが判別できるようになっています.SectionId は,データソースの中ではユニークな値になりますが,他のデータソースのデータセクションとは,同じ値が割り振られる可能性があります.DataSourceId と SectionId を両方使うことで,システム全体でユニークな識別番号となります.
データセクションは,そのセクションデータが保持するデータ形式に応じて,以下の種類があります.
- indexed
- 可変長配列に対応するデータ構造です.セクションデータは可変個のエレメントデータから構成され,各エレメントデータは固定長のアドレス値とデータ値を持っています.CAMAC の ADC など,データが単純な整数値の集合からなる場合などに利用されます.以下は,indexed セクションデータの例です.
0 123 -- element data -+
1 234 -- element data | -- section data
2 213 -- element data -+
0 312
1 231
2 312
- tagged
- 構造体に対応するデータ構造です.セクションデータは名前の付けられた固定数個のエレメントデータから構成され,各エレメントデータは固定長のデータ値を持ちます.indexed と似た構造のデータに対し,各エレメントデータの意味を強調したい場合に使用します.以下は,tagged セクションデータの例です.
pmt_0 123 -- element data -+
pmt_1 234 -- element data | -- section data
pmt_2 213 -- element data -+
pmt_0 312
pmt_1 231
pmt_2 312
- block
- 構造のない(構造の分からない)データブロックを保持するデータ構造です.可変サイズのデータブロックを保持でき.データサイズのみが管理されます.内部にバッファを持ったモジュールからのデータなどで使われます.
- nested
- 任意のセクションを任意数保持できるものです.nested のセクション自体を保持することもできます.ネストにより,複雑なデータ構造を表現できるようになっています.
データデスクリプタ
各データソースは,全てのデータパケットの送出に先立って,データデスクリプタと呼ばれる特殊なパケットを送り出します.データデスクリプタには,そのデータソースのデータソース名および DataSourceId,そのデータソースから送られるパケットのデータセクションの構造とセクション名および SectionId などが記録されています.データパケット自体には DataSourceId と SectionId しか記録されていないので,データパケット内のデータの解釈には,このデータデスクリプタの情報が必要になります.
また,データデスクリプタには,データソースアトリビュートと呼ばれる「名前・値」ペアを記録するフィールドもあります.これは,測定系のパラメータなど,データ自体には含まれない情報を記録するために使われます.
以下は,データデスクリプタの例です.詳細については,ここではあまり気にしないでください.
datasource "CamacAdcTdc"<1025>
{
attribute creator = "KinokoCollectorCom";
attribute creation_date = "2003-04-13 17:40:23 JST";
attribute script_file = "CamacAdcTdc.kts";
attribute script_file_fingerprint = "edddd900";
section "adc"<256>: indexed(address: int-8bit, data: int-24bit);
section "tdc"<257>: indexed(address: int-8bit, data: int-24bit);
}
datasource "MyComplicatedMeasurement"<5>
{
attribute creator = "KinokoCollectorCom";
attribute creation_date = "2003-04-13 17:47:43 JST";
attribute script_file = "MyComplicatedMeasurement.kts";
attribute script_file_fingerprint = "5f36e1a0";
attribute setup_version="1.0";
section "event"<6>: nested {
section "event_info"<3>: tagged {
field "time_stamp": int-32bit;
field "trigger_count": int-32bit;
}
section "adc"<4>: indexed(address: int-8bit, data: int-24bit);
section "tdc"<5>: indexed(address: int-8bit, data: int-24bit);
}
section "hv_monitor"<7>: indexed(address: int-16bit, data: int-16bit);
}
パケット構造
参考までに,各パケットの構造を以下に示します.ほとんどの場合,ユーザはパケットの物理的構造を意識する必要はありません.全てのパケットには DataSourceId が,データパケットにはそれに加えて SectionId が記録されているという点のみ留意しておいてください.
バイトオーダは,パケットを生成した計算機のバイトオーダになります.最初の 32bit ワードに 16bit の DataSourceId が記録されているので,最初のワードの値と 0x0000ffff のビットアンドを取ることにより,バイトオーダを判別することができるようになっています.
KDFファイル
Kinoko では,簡易データストレージとして,KDF 形式と呼ばれるフォーマットのデータファイルを生成します.KDF には,全てのデータに加えて,データを取ったときの測定条件や使用したスクリプトファイル名など,必要な情報のほとんどが記録されています.また,バイトオーダの自動変換や,データ圧縮などの機能も持っています.オンラインデータパケットをほぼそのままの形でファイルに記録するため,比較的高速に動作します.
一方で,KDF は,オンライン用の簡易データストレージとして設計されているため,ファイル中のデータのランダムアクセスなどがあまり得意ではありません.このため,巨大ファイルを大量に扱うような実験において,オフラインアナリシスと共有するようなデータストレージに KDF を使用することは適切ではありません.そのような実験では,しばしばその実験用にデザインされたデータストレージシステムが別に準備されることが多いので,Kinoko ではユーザコンポーネントとしてそのストレージ用の Recorder を作成することが想定されています.
ファイル構造
参考として,KDF ファイルの構造を以下に示します.ただし,パケット構造と同様に,ユーザは KDF ファイル構造の詳細を意識しなければならないことはほとんどないはずです.
ファイル先頭の 256 byte は,自由に使える領域で,KDF を読むツールはこの部分を完全に無視します.通常は,KDF ファイルに関する簡単な説明がプレインテキストで書かれていて,cat などで KDF ファイルを見たときに,kdfdump などのツールを使うように促すメッセージが表示されるようになっています.
次のプリアンブル(Preamble)には,データファイル自体に関するパラメータが記録されています.
具体的には,ファイルのマジックナンバやデータフォーマットのバージョン,続くヘッダやデータブロックなどのファイルオフセットなどです.バージョン番号は 16bit のメジャーバージョンと 16 bit のマイナバージョンから構成され,下位互換性のある変更に関してはマイナバージョンだけが変更されることになっています.これにより,古いプログラムで新しいデータを読む場合でも,互換性が許す限りデータを正しく扱えるようになっています(もちろん,非互換性が検出された場合にはエラーとなります).さらに,データファイルを構成する各ブロック毎にバージョン番号を持たせることにより,一部が非互換の場合でも互換の部分は読むことができるようにしてあります.
ストレージヘッダ(Storage Header)には,外部から渡されたランパラメータなどが,テキスト形式で記録されています.以下は,ストレージヘッダの例です.
[Header]
{
Creator="KinokoRecorderCom";
DateTime="2003-04-14 10:47:24 JST";
UserName="sanshiro";
Host="kinoko.awa.tohoku.ac.jp";
Directory="/home/sanshiro/work/kinoko/local/test";
RunName="test001";
Comment="this is a test";
}
データ領域(Data Area) は,データストリームのデータパケットが,ほぼそのままの形で記録されています.ただし,パケット自体にはパケットサイズが明示的に記録されていないことと,次のパケットのサイズをそのパケットを読む前に知りたいという情况が多いことから,各パケットデータの直前に,そのパケットのサイズがリトルエンディアンの 4byte 整数で記録されています.パケットの中身のバイトオーダは,異なったデータソースからのパケットが混在しているため,パケットごとに判断する必要があります.
KDF サブファイル
OS によるファイルサイズの上限の問題を避けるためと,コピーや管理などの便宜のため,Kinoko は KDF ファイルが大きくなると,それを複数のサブファイルに分割します.ファイルの分割はパケットの区切りで行なわれますが,その際単純に次のファイルを作成してそこへ記録を続けるだけなので,2つめ以降のサブファイルにはプリアンブルやヘッダなどは含まれません.このため,通常のツールでサブファイルだけを読もうとすると,inconsistent magic number などのエラーが出て,正しく扱うことができません.
% ls -la
-r--r--r-- 1 daq kamland 268436820 Apr 16 10:01 run2459.kdf
-r--r--r-- 1 daq kamland 268436868 Apr 16 10:06 run2459.kdf.1
-r--r--r-- 1 daq kamland 268435480 Apr 16 10:11 run2459.kdf.2
-r--r--r-- 1 daq kamland 268438236 Apr 16 10:16 run2459.kdf.3
% kdfdump run2459.kdf.2
ERROR: TKinokoKdfStorage::ReadPreamble(): inconsistent magic number
%
KDF はオンライン用の簡易ストレージとして設計されているため,サブファイル自体には意味上の構造はなく,それを単体で読むことは想定されていません.ただし,デバッグやオンサイトアナリシスなどの目的のため,若干のサポートはあります.
kdfextract ユーティリティを使うと,先頭の KDF ファイルからファイルヘッダ,ストレージヘッダおよび RunBegin パケットを抽出できます.同時に,kdfextract は対応する RunEnd パケットを生成し,別のファイルに書き出します.これらを利用することにより,サブファイルをひとつの完結したファイルとして処理を行うことができるようになります.
% kdfextract run2459.kdf
making run2459-RunBegin.kdf...
making run2459-RunEnd.kdf...
% cat run2459-RunBegin.kdf run2459.kdf.2 run2459-RunEnd.kdf > run2459-2.kdf
% kdfdump run2459-2.kdf
この作業をする際にオリジナルのデータファイルを上書き削除しないように十分注意してください.全てのデータファイルにあらかじめ書き込み禁止属性を設定しておくことを勧めます.
KDF には raw アクセスモードがあり,これによりプリアンブルやストレージヘッダなどを無視して,直接データパケットを読むことができます.また,プリアンブルなどがないファイル(2番目以降のサブファイル)でも,データパケットのみに直接アクセスしてその内容を読み出すことができます.
% kdfcheck --raw run2459.kdf.2
各パケットの識別にはその DataSourceId や SectionId の解釈が必要ですが,読み出しスクリプト等においてこれらを指定した値に固定することができます.これにより,データデスクリプタを読まなくても,パケットを識別し,データブロックを取得することが可能になります.
ただし,これらは全ていわば裏技で,Kinoko のエラーチェックやパラメータ管理などの機能を全て無視していることに注意してください.
スクリプトの基本
Kinoko では,システムの構成を記述したり,各コンポーネントの動作をカスタマイズしたりするために,スクリプトを使用します.
使われるスクリプト言語の文法は,その用途によりいろいろと拡張されていますが,基本となる部分は共通です.ここでは,この基本部分 (KinokoScript) について説明します.
KinokoScript の処理系として,kinoko-script コマンドがあります.スクリプトファイルを引数に kinoko-script を実行すると,そのスクリプトを実行します.
% cat hello.kino
println("hello, world.");
% kinoko-script hello.kino
hello, world.
%
kinoko-script を引数なしで実行すると,プロンプトを表示し,1行づつ対話的に実行できます.
% kinoko-script
> println("hello, world.");
hello, world.
> 1+2*3;
7
> for (int i = 0; i < 3; i++) {
? println(i + ": hello");
? }
0: hello
1: hello
2: hello
> .q
%
スクリプトを実行した後にプロンプトで対話的に処理を続けたい場合は,--interactive または -i オプションを指定します.
% kinoko-script hello.kino -i
hello, world.
> sqrt(2);
1.41421
> .q
%
KinokoScript の文法は C/C++ をベースに構成してあり,基本的な部分は共通です.以下は,C/C++ との相異点を中心に説明します.
型と変数
値,型とリテラル
kinoko-script には,C/C++ と同様に,整数値,実数値および真偽値があります.文字列は C とは異なり,文字の配列ではなく文字列として扱われます.kinoko-script には,これらに加えて,複素数を表現するための「虚数値」および配列と構造体を融合したような「リスト」が定義されています.以下は,これらの型とリテラル表現の例です.
虚数は実数または整数の末尾に i を付けて表現します.
複素数のリテラルはありませんが,実数と虚数を組み合わせて表現できます.
println(log(-1+1i));
println(sqrt(-2.0));
println(sqrt(-2+0i));
println(sqrt((complex) -2));
i 単体では変数となってしまい,虚数の表現にはならないことに注意してください.虚数単位のリテラルは 1i (いちアイ) です.
以下に文字列の使い方の例を示します.
println("hello" + " " + "world");
println("pi = " + 3.1415);
println((int) "123" * 2);
println(sizeof("hello world"));
println("hello world"[6]);
以下はリストの使い方の例です.
println({123, 456, "hello"}[1]);
println({123, 456, "hello"}[{1,2}]);
println({1, 2, "hello"} + {3, 4, " world"});
println(2 * {0, 1, 2} + 1);
println(exp({0, 1, 2}));
println({1, 2} <+> {3, 4});
println({1, 2, 3, 4, 6, 12} <&> {1, 2, 4, 8, 16});
リテラルではありませんが,規則的な整数や実数のリストは,リスト生成演算子 [] を使って簡単に生成することができます.
println([0, 5]);
println([0, 10, 2]);
println([5, 0]);
println([0, 5] ** 2);
型宣言名
以下はバリアント変数の使い方の例です.
variant a = 123;
println(typeof(a));
println(a + 456);
a = "123";
println(typeof(a));
println(a + 456);
a = { 123, "123" };
println(typeof(a));
println(a + 456);
バリアント変数は,$ をつけることにより宣言せずに使うことができます.この変数のスコープは常にグローバルです.
for ($i = 0; $i < 10; $i++) {
$sum += $i;
}
println($sum);
リストは,通常の整数インデクスの他に,文字列キーを使ってアクセスすることもできます.
list range;
range{"min"} = 0;
range{"max"} = 10;
println(range);
println(keys(range));
println(range{"max"});
演算子と式
算術演算,関係演算や代入などの基本的な演算子は全て C/C++ と同様に使用できます.以下は C/C++ と同じ動作をする演算子の一覧です.
以下の演算子は C/C++ にもありますが,動作が若干異なります.
以下の演算子が独自に追加されています.
冪乗演算子 ** が通常の2項演算子ではなく特殊演算子になっているのは,
-3**2 が -9 となるようにするためです.
文と制御構造
条件分岐やループなどの文は全て C/C++ と同様に使用できます.以下は C/C++ と同じ動作をする文の一覧です.
以下の文は C/C++ と似ていますが,若干異なった振舞いをします.
以下の文は C/C++ にはないものですが,Perl などの多くのスクリプト言語にあるものと同様のものです.
以下に foreach 文の使い方の例を示します.
list member_list = { "Taro", "Jiro", "Saburo" };
foreach ($member; member_list) {
println($member);
}
関数定義,その他エントリ
C/C++ と同様の形式で関数を定義できます.
関数定義: 戻り値型 関数名 ( 仮引数リスト ) { 文 }
関数の呼び出しも,C/C++ と同様に,関数呼び出し演算子を使用します.
関数呼び出し: 関数名 ( 仮引数リスト )
C/C++ では,実行可能な文は全て関数またはメンバ関数の内部に記述されている必要がありましたが,kinoko-script では,関数の外でも文を記述することができます.これらの文は,kinoko-script の実行が開始された直後に記述された順で実行されます.
関数のように,スクリプトの実行開始点を規定するものを kinoko-script ではエントリと呼びます.関数の外に記述された個々の文も,スクリプト開始直後に実行するように指定されている(疑似)エントリです.エントリには他に,別のファイルの中身を取り込むように指示する include (疑似)エントリがあります.
以下は kinoko-script で規定されているエントリの一覧です.
- 関数定義エントリ
- 構文: 戻り値型 関数名 ( 引数リスト ) { 文 }
- include 疑似エントリ
- 構文 include "ファイル名";
指定されたファイルをその位置に取りこむ.
- 文 疑似エントリ
- どの実行エントリにも属さない文を定義する.これらの文は,エントリが実行される直前に,定義された順で自動的に実行される.
組み込みクラスと組み込み関数
入出力関係
組込み関数
- void print(string line)
- 引数に与えられた文字列を標準出力に書き出す.
- void printLine(string line) / void println(string line)
- 引数に与えられた文字列を標準出力に書き出し,改行する.
- void putByte(int byte) / void putc(int byte)
- 引数に与えられた値を標準出力に1バイトとして書き出す.
- string getLine() / string getln()
- 標準入力から一行読み込み,その文字列を返す.返される文字列は改行文字を含む.EOF の場合,空文字列を返す.
- int getByte() / string getc()
- 標準入力から1バイトを読み,その値を返す.EOF の場合,-1 を返す.
- string readLine() / string readln()
- getLine() と同じ機能だが,GNU/readline ライブラリがリンクされている場合,入力に行編集機能が利用できる.
InputFile クラス
InputFile file("source.cc");
string line;
int line_count = 1;
while (line = file.getLine()) {
println(line_count + ": " + line);
line_count++;
}
- InputFile(string file_name)
- コンストラクタ.ファイルを入力モードでオープンする.
- string getLine() / string getln()
- ファイルから一行読み込み,その文字列を返す.返される文字列は改行文字を含む.EOF の場合,空文字列を返す.
- string getByte() / string getc()
- ファイルから1バイトを読み,その値を返す.EOF の場合,-1 を返す.
- 標準入力は,InputFile クラスの定義済みオブジェクト cin としてアクセスできます.
OutputFile クラス
OutputFile file("sine_table.dat");
double pi = acos(-1);
for (double x = 0; x < 2*pi; x += pi/100) {
file.println(x + " " + sin(x));
}
- OutputFile(string file_name)
- コンストラクタ.ファイルを出力モードでオープンする.
- void print(string line)
- 引数に与えられた文字列をファイルに書き出す.
- void printLine(string line) / void println(string line)
- 引数に与えられた文字列をファイルに書き出し,改行する.
- void putByte(int byte) / void putc(int byte)
- 引数に与えられた値を標準出力に1バイトとして書き出す.
- 標準出力は,OutputFile クラスの定義済みオブジェクト cout としてアクセスできます.
- 標準エラー出力は,OutputFile クラスの定義済みオブジェクト cerr としてアクセスできます.
InputPipe クラス
InputPipe pipe("zcat mydata.dat.gz");
while ($line = pipe.getLine()) {
//...
}
- コンストラクタ引数のコマンドを実行し,その出力を取り込みます.
- InputFile クラスの全てのメソッドが同じ型式で利用できます.
OutputPipe クラス
- コンストラクタ引数のコマンドを実行し,このオブジェクトの print()/println() 出力をコマンドへの入力に結びつけます.
- OutputFile クラスの全てのメソッドが同じ型式で利用できます.
書式化
組込み関数
- string dec(int value, int width)
- 引数に与えられた整数値を10進表記の文字列に変換する
- string hex(int value, int width)
- 引数に与えられた整数値を16進表記の文字列に変換する
- string bin(int value, int width)
- 引数に与えられた整数値を2進表記の文字列に変換する
- string fixed(float value, int precision)
- 引数に与えられた実数値を固定小数点表記の文字列に変換する
- string scientific(float value)
- 引数に与えられた実数値を科学表記の文字列に変換する
Formatter クラス
Formatter クラスは数値などから書式化した文字列を生成するためのもので, C++ の ostream と同様の機能を同様の形式で提供します(C++ の挿入演算子 << は put() メソッドになります).
Formatter formatter;
string line = formatter.put("pi=").setPrecision(10).put(3.14159265).flush();
println(line);
println(Formatter().put("pi=").setPrecision(10).put(3.14159265).flush());
- Formatter& put(int value)
- Formatter& put(float value)
- Formatter& put(complex value)
- Formatter& put(string value)
- 引数の値を内部バッファに挿入する.
- string flush()
- 内部バッファの内容を文字列にして返す.
- Formatter& setWidth(int width)
- 次に挿入される値の表示幅の最小値を指定する.
- Formatter& setPrecision(int precision)
- 浮動小数点数を表示する際の表示精度を指定する.
- Formatter& setFill(string character)
- 表示幅を埋めるための文字を指定する.
- Formatter& setBase(int base)
- 整数を表示する際の基数を指定する.
- Formatter& hex()
- 整数を表示する際の基数を 16 進数に設定する.
- Formatter& dec()
- 整数を表示する際の基数を 10 進数に設定する.
- Formatter& fixed()
- 浮動小数点数を固定小数点型式で表示するように設定する.setPrecision() で設定する精度は小数点以下の桁数の最大値となる.
- Formatter& scientific()
- 浮動小数点数を科学型式で表示するように設定する.setPrecision() で設定する精度は桁数の最大値となる.
Scanner クラス
Scanner クラスは C++ の istream に似た機能を提供します(C++ の抽出演算子 >> は get() メソッドになります).
string line;
double x, y, z;
while (line = getln()) {
Scanner scanner(line);
if (scanner.get(x).get(y).get(z).good()) {
//...
}
}
string line;
double x, y, z;
while (line = getln()) {
if (Scanner(line).get(x).get(y).get(z).good()) {
//...
}
}
- Scanner(string value)
- コンストラクタ.引数に渡された文字列を内部バッファに取りこむ.
- Scanner& load(string value)
- 引数に渡された文字列を内部バッファに取りこむ.
- Scanner& get(int& value)
- Scanner& get(float& value)
- Scanner& get(complex& value)
- Scanner& get(string& value)
- Scanner& get(variant& value)
- 内部バッファをスキャンして,対応する文字列から値を取りだす.
- Scanner& getLine(string& line, string terminator = "\n")
- terminator 引数に指定された終端文字までを内部バッファから読み出し,line に返す.終端文字はバッファからは取り除かれるが,line に返される文字列には含まれない.
- Scanner& skipWhiteSpaca()
- 内部バッファの先頭から連続する空白文字を取り除く.
- Scanner& setBase(int base) / Scanner& setbase(int base)
- 整数を読み出す際の基数を指定する.
- int isGood() / int good()
- 前回の get() に成功した場合は 1 を,失敗した場合は 0 を返す.
- int lastGetCount() / int gcount()
- 前回の get() で読みこんだ文字数を返す.
数学関数
数学関数
変換関数
乱数生成
- float srand(int seed)
- float rand()
リスト処理関数
統計演算
- int length(list x)
- float min(list x)
- float max(list x)
- float sum(list x)
- float mean(list x)
- float deviation(list x) / float rms(list x)
リスト演算
- list delta(list x)
- リストの差分をとる
- list sigma(list x)
- リストの和分をとる
リスト処理
- list divide(list x, int n)
- リストを指定長さごとに分割する
- list zeros(int n)
- 値が全て 0 の長さ n のリストを生成する
- list ones(int n)
- 値が全て 1 の長さ n のリストを生成する
- int count(list x)
- 引数のリストから bool にキャストして true になる要素数を数える
- list find(list x)
- 引数のリストから bool にキャストして true になる要素のインデクスのリストを返す
文字列処理関数
これらの文字列処理関数は,基本的に Perl の同名の関数と同じ動作をします.
- string substr(string str, int offset, int length)
- string substr(string str, int offset)
- str の部分文字列(offset から length 文字)を取りだす.length が省略された場合文字列の末尾までが取りだされる.length が負の場合は末尾から -length 文字を残すように長さが調節される.
- int index(string str, string substr, int offset=0)
- str の中の offset 以降で substr が最初に出現する位置を返す.substr が存在しない場合は -1 を返す.
- string chop(string str);
- str の末尾の1文字を str から削除し,削除した文字を返す.
- int chomp(string str);
- str の末尾にある改行文字を str から削除し,削除した文字数を返す.
その他 組込み関数
シェル・プロセス制御・環境変数
- int system(string command)
- シェルを起動し,引数のコマンドをシェルから実行する.コマンドの実行が終了するまで system() を呼び出したスクリプトは実行を停止する.
- string shell(string command)
- シェルを起動し,引数のコマンドをシェルから実行し,コマンドの標準出力を文字列にして返す.コマンドの実行が終了するまで shell() を呼び出したスクリプトは実行を停止する.
- int execute(string path, string ...)
- 第一引数に指定されたプログラムを子プロセスとして実行する.関数は任意の数の引数をとり,それらは子プロセスの起動引数になる.子プロセスの起動に成功した場合はそのプロセスIDを,失敗した場合は -1 を返す.
- int wait() / int wait(int process_id)
- 引数に指定したプロセスIDを持つ子プロセスが終了するまで実行を停止する.子プロセスがすでに終了している場合は,関数は即座にリターンする.引数に指定できる子プロセスは execute() 関数で実行した子プロセスのみ.引数を省略した場合,いずれかの子プロセスが終了するまで実行を停止する.すでに終了し,ゾンビになっている子プロセスが存在する場合,関数は即座にリターンする.
- int kill(int process_id, int signal_id = SIGTERM)
- 引数に指定したプロセスIDをもつプロセスに引数に指定したシグナルを送る.
- void sleep(int time_sec) / void sleep(int time_sec, int time_usec)
- 引数に渡された時間が経過するまでスクリプトの実行を停止する.
- string getEnvironmentVariable(string name)
- 引数に渡された名前の環境変数を取得する.環境変数が定義されていない場合は,空文字列を返す.
- void setEnvironmentVariable(string name, string value)
- 引数に指定された名前の環境変数に引数に指定された値を設定する.
時刻
- int time()
- 現在時刻を UNIX 時間で返す.
- int timeOf(int year, int month, int day, int hour, int minute, int second)
- 引数に指定された時刻を UNIX 時間で返す.
- string localTime() / string localTime(string time_format)
- 現在時刻を time_format に従って整形し,その文字列を返す.time_format が指定されていない場合,そのシステムのデフォルトのフォーマットで整形する.
- string localTimeOf(int time_value) / string localTimeOf(int time_value, string time_format)
- 引数に指定された時刻を time_format に従って整形し,その文字列を返す.time_format が指定されていない場合,そのシステムのデフォルトのフォーマットで整形する.時刻の表現は UNIX 時間.
プログラム引数
- int numberOfArguments()
- プログラムに渡された引数の数を返す.第1引数はスクリプト名.
- string getArgumentOf(int index)
- プログラムに渡された引数のうち index 番目のものを返す.第1引数はスクリプト名.
- int numberOfParameters()
- プログラムに渡された引数のうち,オプション(- からはじまるもの)と第一引数(スクリプト名)を除いたもの(パラメータ)の数を返す.
- string getParameterOf(int index)
- プログラムに渡された引数のうち,オプション(- からはじまるもの)と第一引数(スクリプト名)を除いたもの(パラメータ)の index 番目のものを返す.
- int isOptionSpecified(string option_name)
- プログラムに渡された引数のうち,-option_name,--option_name, -option_name=value, --option_name=value となっているものがあれば真を返す.
- string getOptionValueOf(string option_name)
- プログラムに渡された引数のうち,-option_name=value, --option_name=value となっているものがあれば,その value の値を返す.
- bool IsSwitchSpecified(string switch_character)
- プログラムに渡された引数のうち,-switch_character としてあたえられた文字があれば,真を返す.
ファイルシステム
- void makeDirectory(string directory_name)
- 新しいディレクトリを作成する.
- string currentDirectory(void)
- カレントディレクトリ名を返す.
- void changeDirectory(string directory_name)
- 引数のディレクトリをカレントディレクトリに設定する.
その他
- variant eval(string expression)
- 引数の文字列に書かれた式を KinokoScript の文法にしたがって評価し結果を返す.expression 内では,eval() が呼ばれたときに有効な変数を参照できる.
正規表現
正規表現の基本的な構文は以下のとおりです.
文字列値 =~ m/パターン/オプション
文字列値 !~ m/パターン/オプション
文字列値 =~ s/パターン/置換文字列/オプション
m/パターン/ は =~ 演算子の左辺の値に対して正規表現マッチを行い,マッチした文字列のリストを返します.先頭の m は省略可能です.!~ は,=~ と同等のマッチを行いますが,マッチしなかったときに true を,マッチしたときに false を返します.
s/パターン/置換文字列/ は =~ 演算子の左辺の値に対して正規表現マッチを行い,マッチした部分を 置換文字列 で置き換えます.=~ 演算子の左辺の値が左辺値の場合,置換後の文字列が代入されます.
オプションに指定できる文字と意味は以下のとおりです.
| g | グローバルマッチを行う |
| i | 大文字小文字を区別しない |
以下にいくつかの例を示します.
単純なマッチ
string text = "cosine";
if (text =~ m/sin/) {
println("matches");
}
サブマッチ
string text1 = "cosine";
list result1 = (text1 =~ m/(.+)(sin(.*))/);
println(result1);
string text2 = "tangent";
list result2 = (text2 =~ m/(.+)(sin(.*))/);
println(result2);
置換
string text = "She sells sea shells.";
text =~ s/sea/C/;
println(text);
グローバルマッチオプションをつけると,マッチした全ての文字列を置換します.
string text = "She sells sea shells by the sea shore.";
text =~ s/sea/C/g;
text =~ s/shore/show/;
println(text);
今のところ,置換文字列中でのサブパターンの使用はできません.
分解
string line = "022-(217)-6727";
list elements = split(line, /[-()]+/);
println(elements)
string line2 = "hello kinoko world";
list elements2 = split(line2);
println(elements2)
SQL データベースインターフェース
方法 1: 普通のやり方
{
string driver_name = "PostgreSQL";
string database_name = "E364";
Database db(driver_name, database_name);
string query = "select * from hv_table where hv > 2000";
QueryResult* result = db.executeSql(query);
int number_of_columns = result->numberOfColumns();
for (int i = 0; i < number_of_columns; ++i) {
print(result->fieldNameOf(i) + " ");
}
println();
println("---");
while (result->next()) {
for (int i = 0; i < number_of_columns; ++i) {
print(result->get(i) + " ");
}
println();
}
delete result;
}
方法 2: 簡単なやり方 その1
{
Database db("PostgreSQL", "E346");
for (int channel = 0; channel < 32; channel++) {
string query = "select hv from hv_table where channel=" + channel;
int hv = db.getValueOf(query);
}
}
方法 3: 簡単なやり方 その2
{
Database db("PostgreSQL", "E346");
sql[db] "select channel hv from hv_table" {
println(@channel + ": " + @hv);
}
}
Ntuple
KinokoScript の Ntuple は表形式のデータの入出力に対するシンプルで強力なインターフェースです.テキストファイルを読み込み,リストの集合としてアクセスできます.
% cat runlist.knt
1 pedestal 15.0 /data/run01.kdf
2 calibration 15.0 /data/run02.kdf
3 physics 3743.86 /data/run03.kdf
4 physics 5261.18 /data/run04.kdf
Ntuple nt("runlist.knt");
println(nt[0]);
println(nt{3});
入力ファイル中の # で始まる行はコメントとして読み飛ばされます.行頭の # をコメント記号として解釈したくない場合はバックスラッシュでエスケープしてください("\#").空行はある種のデータ区切りとして使われることもありますが,それが必要でない場面では無視されます.
ファイルの先頭で 「# 名前: 値」の形式で書かれたコメントは「プロパティ」として認識され,スクリプトから読み出すことができるようになります.
特殊なプロパティとして,各カラムに名前をつける "Fields" プロパティがあり,これが指定されているとカラムに名前でアクセスできるようになります.
% cat runlist.knt
# Name: Run List
# Creator: Kinoko Taro
# Fields: RunNumber Type Length FileName
1 pedestal 15.0 /data/run01.kdf
2 calibration 15.0 /data/run02.kdf
3 physics 3743.86 /data/run03.kdf
4 physics 5261.18 /data/run04.kdf
Ntuple nt("runlist.knt");
println(nt.propertyList());
println(nt{"FileName"});
各データ行中の空白はカラムの区切りとして使用されます.もし文字列中に空白文字をデータの一部として使いたい場合,Quote プロパティで引用符を指定します.
% cat runlist.knt
# Name: Run List
# Creator: Kinoko Taro
# Quote: "
# Fields: RunNumber Type Length FileName Comment
1 pedestal 15.0 /data/run01.kdf "No Input Connected"
2 calibration 15.0 /data/run02.kdf "Calibration with Co"
3 physics 3743.86 /data/run03.kdf "Normal Run"
4 physics 5261.18 /data/run04.kdf "Normal Run"
Ntuple nt("runlist.knt");
println(nt[0]);
必要であれば,Delimiter プロパティで区切り文字を指定することができます.Delimiter プロパティと Quote プロパティを同時に使用することもできます.同時に使用した場合,Quote プロパティの解釈が優先され,Quote で囲まれた文字列中の区切り文字は区切り文字として解釈されません.
% cat runlist.knt
# Name: Run List
# Creator: Kinoko Taro
# Quote: "
# Delimiter: ,
# Fields: RunNumber Type Length FileName Comment
1, pedestal, 15.0, /data/run01.kdf, "No Input Connected"
2, calibration, 15.0, /data/run02.kdf, "Calibration with Co, Zn and Hg"
3, physics, 3743.86, /data/run03.kdf, "Normal Run"
4, physics, 5261.18, /data/run04.kdf, "Normal Run"
Ntuple nt("runlist.knt");
println(nt[1]);
Delimiter や Quote プロパティはスクリプト中から指定することもできます.
これにより,CSV など様々な形式のファイルをそのまま読み込むことができます.
% cat runlist.knt
1, pedestal, 15.0, /data/run01.kdf, "No Input Connected"
2, calibration, 15.0, /data/run02.kdf, "Calibration with Co, Zn and Hg"
3, physics, 3743.86, /data/run03.kdf, "Normal Run"
4, physics, 5261.18, /data/run04.kdf, "Normal Run"
Ntuple nt;
nt.setDelimiter(",");
nt.setQuote("\"");
nt.load("runlist.knt");
次は,全く異なった形式のファイルを読む例です.
% cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
kinoko:x:500:500:KiNOKO DAQ Accout:/home/kinoko:/bin/bash
Ntuple nt;
nt.setDelimiter(":");
nt.load("/etc/passwd");
ここまでの例で,各カラムのデータ型が自動で認識されていることに注意してください.KinokoScript は,まずデータを実数で解釈すること試み,できなければ文字列として扱います.整数として解釈したい場合や型を明示的に指定したい場合は FieldTypes プロパティを指定してください.
% cat runlist.knt
# Name: Run List
# Creator: Kinoko Taro
# Quote: "
# Fields: RunNumber Type Length FileName Comment
# FieldTypes: int string float string string
1 pedestal 15.0 /data/run01.kdf "No Input Connected"
2 calibration 15.0 /data/run02.kdf "Calibration with Co, Zn and Hg"
3 physics 3743.86 /data/run03.kdf "Normal Run"
4 physics 5261.18 /data/run04.kdf "Normal Run"
Ntuple nt("runlist.knt");
println(typeof(nt[0][0]);
FieldTypes には,int/long,float/dobule,string および eval が使用できます.eval を指定すると,値が KinokoScript の式として解釈され評価されます.eval を利用すると,list や complex など,KinokoScript の全ての型の値を記録できるようになります.さらに,入力ファイルの先頭に,行頭を #% としてスクリプトを埋め込むことができます.ここで関数を定義すると,eval フィールドからアクセスすることができます.
% cat runlist.knt
# Name: Run List
# Creator: Kinoko Taro
# Quote: "
# Fields: RunNumber Type Length FileName Comment StartTime
# FieldTypes: int string float string string eval
#% string time_format = "%y-%m-%d %H:%M:%S";
#% string date(int unix_time) {
#% return localTimeOf(unix_time, time_format);
#% }
1 pedestal 15.0 /data/run01.kdf "No Input Connected" date(1234567890)
2 calibration 15.0 /data/run02.kdf "Calibration with Co, Zn and Hg" date(1234567900)
3 physics 3743.86 /data/run03.kdf "Normal Run" date(1234569000)
4 physics 5261.18 /data/run04.kdf "Normal Run" date(1234570000)
Ntuple nt("runlist.knt");
println(nt[0]);
eval フィールドや埋め込みスクリプトをうまく組み合わせると,オブジェクトの埋め込みや外部テーブルの動的参照などを実現でき,「スマート」あるいは「リッチ」と呼ばれるような「コンテンツ」を記述できるようになります.
KinokoScript の Ntuple は,gzip 圧縮されたファイルを直接扱うことができます.スクリプトから指定するファイル名に .gz が付いていてもいなくても構いませんが,.gz を付けずに指定して,実際に .knt と .knt.gz の双方が存在する場合には,.knt の方が読み込まれます.
% gzip runlist.knt
% ls
runlist.knt.gz
Ntuple nt("runlist.knt.gz");
Ntuple nt("runlist.knt");
どちらも全く同じように動作するので,スクリプトを変更せずにデータファイルを圧縮することができます.
ディジタル信号処理
高速フーリエ変換 (FFT) の例
int n = 64;
list t = [0, n];
list Vt = sin(84.0 * t/n) + 2*sin(164.0 * t/n) + 5.0;
println(Vt);
Vt *= hammingWindow(sizeof(Vt));
list Vf = fft(Vt);
println(abs(Vf));
list Vt1 = ifft(Vf);
Vt1 /= hammingWindow(sizeof(Vt1));
println(real(Vt1));
離散ウェーブレット変換の例
int n = 256;
list signal = zeros(n);
for (int i = 0; i < n; i++) {
if (i > n/3) signal[i] += 10*exp(-i/(n/6.0));
signal[i] += 0.2*gaussian();
signal[i] += 0.5*signal[i-1];
}
println(signal);
DaubechiesWavelet wavelet(4);
wavelet.transform(signal);
println(signal);
signal *= (int) (abs(signal) > 0.5);
wavelet.inverseTransform(signal);
println(signal);
ディジタルフィルタの例
int n = 2048;
list impulse = zeros(n/2) <+> ones(1) <+> zeros(n/2-1);
list step = zeros(n/2) <+> ones(n/2);
double cutoff_frequency = 0.1;
int number_of_poles = 4;
double max_ripple = 0.1;
ChebychevLowPassFilter filter(cutoff_frequency, number_of_poles, max_ripple);
filter.applyTo(impulse);
println(impulse);
filter.applyTo(step);
println(step);
list f = fft(impulse);
println(abs(f));
組み込み関数
- list fft(list x)
- 引数のリストに対して高速フーリエ変換を行う.引数は complex または float のリスト,戻り値は complex のリスト.引数のリストの長さが2の冪乗でない場合,2の冪乗になるまで後ろに 0 が加えられたものに対して計算される.戻り値のリストの長さは引数のリストの長さと同じ(0 を加えた場合は加えた後の長さ)で,通常の FFT の慣習に従った順序で並べられている.すなわち,最初の要素が周波数 0 (DC) に対応し,中央の点がナイキスト周波数.その先は負のナイキスト周波数から 0 (DC) へ向かって並べられる(入力が実数の場合は正の周波数部分の折り返しとなる).
- list ifft(list x)
- 引数のリストに対して高速逆フーリエ変換を行う.引数および戻り値の意味は fft() に準じる.
- list parzenWindow(int data_length)
- list hanningWindow(int data_length)
- list hammingWindow(int data_length)
- list welchWindow(int data_length)
- list blackmanWindow(int data_length)
- ウィンドウ関数.引数に指定された長さのリストにして返す.
- float sinc(float x) / list sinc(list x)
- sinc() 関数
組み込みクラス
ウェーブレット変換は、ウェーブレットに対応する以下の組み込みクラスで実装されています.
- HaarWavelet
- ハールウェーブレット
- DaubechiesWavelet(int N)
- ドベシィウェーブレット. N は係数の数で、4,6,8,12,16,20 が実装されている
ディジタルフィルタは以下の組み込みクラスで実装されています.周波数はサンプル間隔を 1 として規定されています.したがって,ナイキスト周波数は 0.5 に対応します.
- MovingAverageFilter(float cutoff_freq)
- 移動平均フィルタ.平均をとるサンプル数は cutoff_freq の逆数になる.
- WindowedSincFilter(float cutoff_freq, int kernel_length)
- sinc() 関数形のカーネルに Blackman 窓関数を組み合わせた FIR.
- SinglePoleLowPassFilter(float cutoff_frequency)
- SinglePoleHighPassFilter(float cutoff_frequency)
- 単一ポール(指数関数形時間応答;CR 回路とか)の IIR.
- ButterworthLowPassFilter(float cutoff_freq, int n_of_poles)
- ButterworthHighPassFilter(float cutoff_freq, int n_of_poles)
- バタワース特性の IIR.
- ChebychevLowPassFilter(float cutoff_freq, int n_of_poles, float max_ripple)
- ChebychevHighPassFilter(float cutoff_freq, int n_of_poles, float max_ripple)
- チェビシェフ特性の IIR.
読み出しスクリプト
読み出しスクリプトは,データ読み出しの手順を表現する内部オブジェクトの構造(読み出しシーケンス)を構築するために,KinokoCollector や tinykinoko などによって使用されるスクリプトです.
基本スクリプトに加え,以下の文法要素が追加されています.
- datasource エントリ
- on 文
- when 文
- unit 文
- attribure 文
- invoke 文
- terminate / skip 文
- VmeCrate / VmeController / VmeModule クラス
- CamacCrate / CamacController / CamacModule クラス
- SoftwareModule クラス
- ReadoutChannelList クラス
- Register クラスとオーバロードされた演算子
- DataRecord クラス
- getRegistry() / setRegistry() 関数
- readRegistry() / writeRegistry() 関数
- suspend() 関数
- echo() 関数
- scriptFileName() 関数
読み出しスクリプトはシステムの起動時に一度だけ実行され,読み出しシーケンスを構築します.
読み出しシーケンスとは,デバイスにアクセスしてデータの読み書きを行う一連の手続きを表現した内部オブジェクトの構造です.
読み出しシーケンスはシーケンスの開始条件とともに記述され,データ収集中に開始条件が成立するとそのたびに毎回実行されます.
スクリプトの実行とシーケンスの実行を混同しないように注意してください.
クレート,コントローラ,モジュール
読み出しスクリプトにおいて,まずはじめに行なうことは,使用するデバイスの宣言と,対応するドライバの関連付け,およびそれらの接続を記述することです.
使用するデバイスの宣言は,通常のオブジェクトと同じ構文でおこないます.VME, CAMAC, およびソフトウェアの各モジュール,コントローラ,クレートに対して,それぞれ VmeModule/CamacModule/SoftwareModule, VmeController/CamacController, および VmeCrate/CamacCrate クラスがあります(ソフトウェアモジュールにはコントローラおよびクレートはありません).モジュールおよびコントローラには,その実際のデバイスに対応したドライバ(KinokoModuleDriver, KinokoControllerDriver) のドライバ名をコンストラクタの第1引数に指定します.
datasource CamacAdc {
CamacCrate camac_crate;
CamacController camac_controller("Toyo-CC7x00");
CamacModule adc("Rinei-RPC022");
CamacModule tdc("Rinei-RPC060");
VmeCrate vme_crate;
VmeController vme_controller("SBS-620");
VmeModule latch("SIS_3600");
VmeModule interrupter("Rinei-RPV130");
利用できるモジュールドライバおよびコントローラドライバの一覧は,コマンド kinoko-lsmod で表示させることができます.
% kinoko-lsmod
VME Controllers:
SBS_617:
SBS_618:
SBS_620:
Kinoko_Vmedrv:
Null:
CAMAC Controllers:
Toyo_CC7x00:
Hoshin_CCP:
Kinoko_Camdrv:
Null:
VME Modules:
Generic_MemoryA16D16: VmeMemory (Generic_VmeMemory)
Generic_MemoryA16D32: VmeMemory (Generic_VmeMemory)
(中略)
Hoshin_V004: VmeScaler (Hoshin_V004)
Rinei_RPV130: VmeIORegister (Rinei_RPV130)
Rinei_RPV160: VmeFADC (Rinei_RPV160)
SIS_3600: VmeLatch (SIS_3600)
SIS_3601: VmeOutputRegister (SIS_3601)
SIS_3801: VmeScaler (SIS_3801)
CAMAC Modules:
Generic_Standard: CamacModule (Generic_CamacModule)
Rinei_RPC022: CamacQADC (Rinei_RPC022)
Rinei_RPC060: CamacTDC (Rinei_RPC060)
Rinei_RPC081: CamacFADC (Rinei_RPC081)
(中略)
ここで,コロンの左側がドライバ名,右側がそのモジュールの種別と型番です.ドライバ名は,原則として "製造者_型番" となっています.ドライバ名中のアンダースコアはスクリプト中でハイフンに置き換えることができます.
使用するデバイスを宣言したら,次にそれらの接続を記述します.CAMAC ならどのモジュールをどのステーションに入れるか,VME ならベースアドレスと,必要なら IRQ および割り込みベクタを指定します.これを行なうのが,VmeCrate/CamacCrate の installController()/installModule() メソッドです.
int station;
camac_crate.installController(camac_controller);
camac_crate.installModule(adc, station = 10);
camac_crate.installModule(tdc, staion = 11);
int address, irq, vector;
vme_crate.installController(vme_controller);
vme_crate.installModule(latch, address = 0x01000000);
vme_crate.installModule(interrupter, address = 0x8000, irq = 3, vector = 0xfff0);
8bit の割り込みベクタを使用する場合,installModule() に指定する割り込みベクタの上位 8bit を 0xff で埋めてください(0xf0 -> 0xfff0 など).
ここまでで,デバイスにアクセスする準備が整いました.
読み出しシーケンスとシーケンス開始条件
セットアップの記述が終了したら,次に読み出し手順の記述を行ないます.
Kinoko では,データ収集時におけるスクリプト解釈のオーバーヘッドを避けるため,スクリプトの解釈はデータ収集開始前に一度だけ行ない,そのときに読み出し手順に対応した内部オブジェクトの構造(読み出しシーケンス)を組み立てるようにしています.読み出しシーケンスとは,シーケンスアクションと呼ばれる単純な操作(1モジュールの読み出し,クリア,レジスタアクセスなど)のリストです.データ収集が開始されたあとは,このシーケンスが繰り返し実行されることになります.スクリプトの実行とシーケンスの実行を混同しないように注意してください.
シーケンスは,データ収集中に「シーケンス開始条件」が成立することにより実行されます.シーケンス開始条件には,例えばモジュールからの読み出し要求や,タイマによる指定時間経過の通知などがあります.一つのスクリプト中に複数のシーケンスを記述することができます.全てのシーケンスはそれぞれのシーケンス開始条件を持ちます.スクリプトでは,シーケンスはシーケンス開始条件とともに記述されます.
シーケンスおよびその開始条件の記述は,on 文によって行ないます.
on 文の先頭に開始条件を指定し,その後にシーケンス構築文を続けます.
シーケンス構築文では,シーケンスアクション生成メソッドという特殊なメソッドを呼ぶことにより,シーケンスにシーケンスアクションを追加していきます.
以下は,CAMAC の ADC からデータを読んでクリアする読み出しスクリプトの例です.
ここでは,ADC の LAM によりシーケンスを開始するようにしています.シーケンス構築文では,CamacModule クラスの持っているシーケンスアクション生成メソッド read() と clear() を使って,それぞれ READ アクションと CLEAR アクションを生成し,シーケンスに追加しています.
datasource CamacAdc
{
CamacCrate crate;
CamacController controller("Toyo-CC7x00");
CamacModule adc("Rinei-RPC022");
int station;
crate.installController(controller);
crate.installModule(adc, station = 10);
on trigger(adc) {
adc.read(#0..#3);
adc.clear();
}
}
このスクリプトにより生成されるシーケンスは,コマンド ktscheck で表示させることができます(細かい部分はあまり気にしないでください).
% ktscheck --show-sequence CamacAdc.kts
trigger 2:
.sequence
-> SingleRead adc, 0:1:2:3
-> CommonControl adc, CLEAR
.end
以下は,input_register からのトリガを待って,adc 4 枚の読み出しとクリアを行う例です.スクリプトの実行と構築されるシーケンスの関係を強調するために,若干複雑なスクリプトにしてあります.
list adc_list = { &adc0, &adc1, &adc2, &adc3 };
on trigger (input_register) {
for (int i = 0; i < sizeof(adc_list); i++) {
adc_list[i]->read(#0..#3);
adc_list[i]->clear();
}
}
これにより構築されるシーケンスは以下のようになります.
% ktscheck --show-sequence foo.kts
trigger 2:
.sequence
-> SingleRead adc0, 0:1:2:3
-> CommonControl adc0, CLEAR
-> SingleRead adc1, 0:1:2:3
-> CommonControl adc1, CLEAR
-> SingleRead adc2, 0:1:2:3
-> CommonControl adc2, CLEAR
-> SingleRead adc3, 0:1:2:3
-> CommonControl adc3, CLEAR
.end
スクリプトの実行によりループが展開されていることに注意してください.
なお,このスクリプトから生成されるシーケンスは,以下のスクリプトから生成されるシーケンスと厳密に同等になります.
on trigger (input_register) {
adc0.read(0x000f);
adc0.clear();
adc1.read(0x000f);
adc1.clear();
adc2.read(0x000f);
adc2.clear();
adc3.read(0x000f);
adc3.clear();
}
つまり,前者のように記述しても,実行時のオーバーヘッドには全く差が生じないことになります.
逆に,以下のようにしても,期待どおりの動作はしません.
int count = 0;
on trigger(input_register) {
count++;
if (count > 1000) {
scaler.read(#0);
scaler.clear();
count = 0;
}
}
これは,以下の記述と厳密に同等です
("スクリプト" は一度だけ実行され,その時 if 文の条件は成立しないから).
on trigger(input_register) {
;
}
シーケンス実行時に変数の値を参照したい場合は,以下のようにシーケンスレジスタを使用する
必要があります.詳細は,シーケンスレジスタの項を参照してください.
Register count;
on trigger(input_register) {
count += 1;
when (count > 1000) {
scaler.read(#0);
scaler.clear();
count = 0;
}
}
参考に,このスクリプトから生成されるシーケンスを表示させてみると,以下のようになります.
% ktscheck --show-sequence foo.kts
trigger 2:
.sequence
-> OperateRegister [0x861a348], 1, ADD
-> .sequence conditional ([0x861a348] > 3e8)
-> -> SingleRead scaler, 0
-> -> CommonControl scaler, CLEAR
-> -> OperateRegister [0x861a348], 0, LOAD
-> .end
.end
シーケンスアクション生成メソッド
モジュールオブジェクト (CamacModule / VmeModule / SoftwarModule) には,以下のシーケンスアクション生成メソッドが定義されています.ただし,モジュールによっては,これらの一部のみが実装されていることがあります.詳細については,各モジュールの KinokoModuleDriver リファレンスを参照してください.
- void read(ChannelList channel_list)
- void read(int channel_bits)
- 引数に指定された各チャンネルからデータを1ワードづつ読み出し,indexed 型のデータとしてデータストリームに送り出す.単純な ADC, TDC やスケーラなどで利用される.
- void tagRead(ChannelList channel_list)
- 引数に指定された各チャンネルからデータを1ワードづつ読み出し,引数の ChannelList に指定されているタグを使って tagged 型のデータとし,データストリームに送り出す.
- void sequentialRead(ChannelList channel_list)
- void sequentialRead(int channel_bits)
- 引数に指定された各チャンネルからデータを複数ワード読み出し,indexed 型のデータとしてデータストリームに送り出す.読み出されるデータワード数はモジュールに依存する.FADC や マルチヒット TDC などで利用される.
- void blockRead()
- void blockRead(int address)
- void blockRead(int address, int size)
- モジュールからデータブロックを読み出し,block 型のデータとしてデータストリームに送り出す.FIFO やバッファを持つモジュールの読み出しに向いている.
- void clear()
- void clear(int channel)
- モジュール上のデータをクリアする.実際の振舞いはモジュール依存.
- void enable()
- void enable(int channel)
- モジュールまたはモジュール上の指定されたチャンネルをエネーブルする.実際の振舞いはモジュール依存.
- void disable()
- void disable(int channel)
- モジュールまたはモジュール上の指定されたチャンネルをディスエーブルする.実際の振舞いはモジュール依存.
- void writeRegister(int address, Register register)
- モジュール上の指定されたアドレスに値を書き込む.
- void readRegister(int address, Register register)
- モジュール上の指定されたアドレスから値を読み出し,引数のレジスタに格納する.
- void waitData()
- void waitData(int/Register timeout)
- void waitData(int/Register timeout, Register response)
- モジュールでデータが利用可能になるまで実行を停止する.
- timeout が指定されている場合は timeout 秒を上限にデータを待つ.
- データが来れば response レジスタに 1 を,来なければ 0 を返す.
上記の他,モジュールによって独自のアクション生成メソッドが定義されていることがあります.詳細については,各モジュールの KinokoModuleDriver リファレンスを参照してください.
CamacController には以下のアクション生成メソッドがあります.
- void initialize()
- CAMAC クレートに Z を発行する.
- void clear()
- CAMAC クレートに C を発行する.
- void setInhibition()
- CAMAC クレートに I を設定する.
- void releaseInhibition()
- CAMAC クレートの I をクリアする.
CamacModule には以下のアクション生成メソッドがあります.
- void transact(int F, int A)
- 指定された F と A で CAMAC アクションを実行する.
- void transact(int F, int A, int data)
- void transact(int F, int A, Register data)
- 指定された F, A, data で CAMAC アクションを実行する.data がレジスタなら,結果を data に書き戻す.
- void transact(int F, int A, int data, Register Q, Register X)
- void transact(int F, int A, Register data, Register Q, Register X)
- 指定された F, A, data で CAMAC アクションを実行し,Q および X レスポンスを引数の Q, X レジスタに返す.data がレジスタなら,結果を data に書き戻す.
CAMAC の read() などでは,Q レスポンスが帰ってこないときはデータが存在しないとしてデータストリームには全く何も送り出しません.もし,Q がないということを,特別なデータ値で示したいならば,setInvalidDataValue() 関数を使ってそのことを指定してください.これにより,Q レスポンスの有無にかかわらず,read() は常に値を送り出すようになります.
- void setInvalidDataValue(int value)
- Q レスポンスがないときのデータ値を指定する
シーケンス開始条件とトリガハンドリング
シーケンス開始条件には,以下ように トリガ,トラップ,コマンド の3つの種類があります.
- トリガ
- 構文: on trigger (デバイス)
- デバイスからのサービスリクエスト(後述)でシーケンスを実行する.サービスリクエストの詳細はデバイスに依存するが,一般には,CAMAC なら LAM, VME なら割り込みなどになる.
- トラップ
- 構文: on トラップ名
- ランの開始や終了などの,ある特定のタイミングでシーケンスを実行する.現在定義されているトラップは,run_begin / run_end / run_suspend / run_resume の4つ.
- コマンド
- 構文: on command (コマンド名, パラメータリストopt)
- ユーザのコントロールなど,外部コマンドによりシーケンスを実行する.
on trigger の引数に渡されるデバイスは,読み出し開始などの要求をシステムに通知できる機能を持ったものでなければなりません.これらの要求通知は,通常は CAMAC なら LAM を使って,VME ならば割り込みやモジュール上のレジスタのフラグなどを使って実現されます.
モジュールの読み出し要求がシステムに通知されるようにするためには,対応する KinokoModuleDriver が,サービスリクエスタと呼ばれるインターフェースを実装している必要があります.
サービスリクエスタとは,デバイスの読み出し要求等をシステムに通知するためのインターフェースです.デバイスにより読み出し要求の形式が異なるため,それに対応して,サービスリクエスタにも以下のようないくつかの形式があります.
- WaitForSeriveceRequest()
- サービス要求が出されるか,指定した時間が経過するまで実行をブロックする.
- IsRequestingService()
- サービス要求を出しているか調べる.
- EnableSignalOnServiceRequest()
- サービス要求の際にシグナルを発行するように設定する.
これらのうちどのインターフェースが実装されるかはモジュールおよびコントローラの仕様によります.
同時に接続されるサービスリクエスタの数や,それらに実装されているインターフェースの種類に応じて,Kinoko は以下のうちから適当なハンドリングスキームを選択します.
- シングルトリガソース
- WaitForServiceRequest() を呼び出す.
- ポーリングループ
- 一定時間(1ms)ごとに各デバイスの IsRequestingService() を呼ぶ.
- ポーリングの順はラウンドロビン方式.
- シグナル割り込み & ポーリング
- EnableSinalOnServiceRequest() をしてから,シグナルを待ち,シグナルが来るか一定時間(1sec)が経過したらポーリングを行なう.
datasource 内に on trigger が1つだけの場合,常にシングルトリガソースが選択されます.on trigger が 2 つ以上の場合,全てのサービスリクエスタがシグナルの発行をサポートしている場合はシグナル割り込み&ポーリングが,そうでない場合はポーリングループが選択されます.これらのハンドリングスキームによってシステムのパフォーマンスおよび割り込み応答の速さが大きく影響されることに注意してください.
いくつかの組み合わせについて,利用できるサービスリクエスタのインターフェースを以下に示します.
- VME モジュール + vmedrv
- モジュールが VME 割り込みをサポートしている場合,WaitForServiceRequest() はドライバ内部で VME 割り込みから変換された PCI 割り込みを待つ.
- モジュールが VME 割り込みをサポートしている場合,シグナル割り込みが利用できる.
- IsRequestingService() の実装はモジュール依存.通常利用できる.
- CAMAC モジュール + camdrv (東陽 CC/7x00)
- WaitForServiceRequest() はドライバ内部で LAM から変換された PCI の割り込みを待つ.
- IsRequestingService() は TestLAM (F8) を実行し Q レスポンスを見る.
- シグナル割り込みは(今のところ)利用できない.
- CAMAC モジュール + camdrv (豊伸 CCP)
- WaitForServiceRequest() はドライバ内部で LAM を待つループを実行する.
- IsRequestingService() は TestLAM (F8) を実行し Q レスポンスを見る.
- シグナル割り込みは利用できない.
- ソフトウェアモジュール
- WaitForServiceRequest() は条件が成立するまでインターバルタイマーでスリープする.
- IsRequestingService() の実装はモジュール依存.タイマー系(IntervalTimer, OneshotTimer など) では通常利用できる.
- シグナル割り込みは利用できない.
ポーリングの間隔は Kinoko により適切に設定されますが,setPollingInterval() 関数によってポーリング間隔を指定することができます.また,もし Kinoko が割り込みを選択する場合に割り込みを使用したくない場合,forcePolling() 関数を呼び出すことにより割り込みの使用を回避することができます.
- void setPollingInterval(int interval_usec)
- ポーリングの間隔をマイクロ秒単位で指定する.
- void forcePolling()
- void forcePolling(int interval_usec)
- 割り込み使用の可否にかかわらずポーリングを使用するように指定する.
タイミングコントロール
タイミングトラップ
on run_begin などのトラップを使うと,データ収集における特定のタイミングでシーケンスを実行させることができます.
on run_begin {
output_register.outputPulse(#0);
}
on trigger(adc) {
adc.read(#0..#3);
adc.clear();
}
現在実装されているトラップには,以下のものがあります.
- run_begin
- データ収集開始直後にシーケンスを実行する.
- run_end
- データ収集終了直前にシーケンスを実行する.
- run_suspend
- データ収集が一時中断されるとき,その直前にシーケンスを実行する.
- run_resume
- 中断されていたデータ収集が再開されるとき,その直後にシーケンスを実行する.
また,on command を使用すると,KCOM イベントなどの外部イベントにより起動されるシーケンスを記述することもできます.on command の詳細については,外部イベントインターフェースの項を参照してください.
周期実行
IntervalTimer などのソフトウェアモジュールを使用すると,一定時間間隔でくり返し実行するシーケンスや,一定の時間経過後に実行するシーケンスを記述することができます.
int interval_sec = 0;
int interval_usec = 100000; // 100ms
SoftwareModule timer("IntervalTimer");
on run_begin {
timer.setInterval(interval_sec, interval_usec);
}
on trigger(timer) {
adc.blockRead();
}
SoftwareModule timer("OneShotTimer");
on run_begin {
timer.setInterval(3);
timer.start();
}
on trigger(timer) {
output_register.outputLevel(#0);
}
ディレイ
数ミリ秒から数秒程度の短いディレイをシーケンスに挿入するには,suspend() シーケンスアクション生成関数を用います.複数のシーケンスが同時に実行されることはないので,どこかで suspend() をすると,そのデータソース全体がその時間だけ停止することになります.
SoftwareModule timer("OneShotTimer");
on run_begin {
output_register.outputLevel(#0);
suspend(1, 0);
}
on trigger(adc) {
adc.blockRead();
}
suspend() シーケンスアクション生成関数のインターフェース宣言は以下のとおりです.
- void suspend(int sec, int usec)
- 指定した時間シーケンスの実行を停止する.
データ待ち
サービスリクエスタを実装しているモジュールなら,waitData() アクションによりデータが読み込み可能になるまでシーケンスの実行を一時停止できます.
int timeout_sec = 1;
on trigger(adc) {
adc.read(#0..#3);
tdc.waitData(timeout_sec);
tdc.read(#0..#3);
}
シーケンスレジスタ
シーケンスレジスタとは,シーケンス中において変数のように扱えるデータ領域です.
シーケンス実行時に値の評価・操作が行えますが,通常の演算子は使用できず,
行える演算も限られています.また,保持できる値は整数のみです.
Register reg;
on run_begin {
reg = 0;
}
on trigger(timer) {
reg += 1;
output_register.writeRegister(address = 0, reg);
}
現在利用できる演算は以下のとおりです.右辺の value には,整数値かレジスタを使用できます.
- register = value
- 左辺のレジスタに右辺の値を代入する.
- register += value
- 左辺のレジスタに現在の値と右辺の値の和を代入する.
- register -= value
- 左辺のレジスタに現在の値と右辺の値の差を代入する.
- register *= value
- 左辺のレジスタに現在の値と右辺の値の積を代入する.
- register /= value
- 左辺のレジスタに現在の値と右辺の値の商を代入する.
- register %= value
- 左辺のレジスタに現在の値と右辺の値の剰余を代入する.
- register &= value
- 左辺のレジスタに現在の値と右辺の値のビット論理積(bitwise AND)を代入する.
- register |= value
- 左辺のレジスタに現在の値と右辺の値のビット論理和(bitwise OR)を代入する.
- register ^= value
- 左辺のレジスタに現在の値と右辺の値のビット排他的論理和(bitwise eXclusive OR)を代入する.
- register <<= value
- 左辺のレジスタの値を右辺の値だけ左にビットシフトさせる.
- register >>= value
- 左辺のレジスタの値を右辺の値だけ右にビットシフトさせる.
スクリプトのデバッグなどの用途のために,レジスタの値を画面に表示するアクション dump() があります.
datasouce RegisterTest {
SoftwareModule timer("IntervalTimer");
Register trigger_count;
on trigger(timer) {
trigger_count += 1;
trigger_count.dump();
}
}
echo() アクションを使っても,レジスタの値を表示させることができます.
datasouce RegisterTest {
SoftwareModule timer("IntervalTimer");
Register trigger_count;
on trigger(timer) {
trigger_count += 1;
echo("trigger counts are: ", trigger_count);
}
}
これらスクリプトを tinykinoko で実行すると,プログレスバーの表示などと干渉して画面が乱れるので,--quiet(または-q)オプションを指定してください.
% tinykinoko RegisterTest.kts foo.kdf --quiet
trigger_count: 1
trigger_count: 2
trigger_count: 3
^C
%
条件付きシーケンス実行
when 文を使うと,シーケンスレジスタの値に応じて,特定のシーケンスのみを実行するようにすることができます.
Register reg;
on trigger(input_register) {
input_register.readRegister(address = 0, reg);
when (reg == 0x0001) {
adc_01.read();
}
when (reg == 0x0002) {
adc_02.read();
}
}
レジスタに対して利用できる関係演算子(レジスタ関係演算子)は以下のとおりです.演算子の意味や結合準位は通常の関係演算子と同じですが,左辺はレジスタ,右辺は整数値またはレジスタでなければなりません.また,戻り値は特殊な「レジスタ論理値」型となります.この型の値は when 文の条件式でのみ意味を持ちます.
- register == value
- レジスタの値が value に等しいとき true を返す.
- register != value
- レジスタの値が value に等しくないとき true を返す.
- register < valeue
- レジスタの値が value よりも小さいとき true を返す.
- register <= value
- レジスタの値が value より小さいか等しいとき true を返す.
- register > value
- レジスタの値が value より大きいとき true を返す.
- register >= value
- レジスタの値が value より大きいか等しいとき true を返す.
- register & value
- レジスタの値と value のビット論理積 (bitwise AND) が 0 でないとき true を返す.
- register ^ value
- レジスタの値と value のビット排他的論理和 (bitwise eXclusive OR) が 0 でないとき true を返す.
さらにレジスタ論理値に対して,以下の論理演算子を利用できます.戻り値はおなじくレジスタ論理値型です(ネストして使用できます).
- ! register_bool
- 論理反転:register_bool の値が false のとき true を返す.
- register_bool && register_bool
- 論理積:右辺値と左辺値がともに true の場合 true を返す.
- register_bool || register_bool
- 論理和:右辺値と左辺値のどちらかが true の場合 true を返す.
データレコード
データレコードは,レジスタの値をデータストリームに送るためのオブジェクトです.
複数のレジスタに名前を付けて tagged 型のデータとしてストリームに送り出します.
DataRecord run_header_record;
DataRecord event_count_record;
Register event_count;
on run_begin {
discriminator.writeRegister(address = 0, threshold_00);
discriminator.writeRegister(address = 1, threshold_01);
run_header_record.fill("Threshold-00", threshold_00);
run_header_record.fill("Threshold-01", threshold_01);
run_header_record.send();
event_count = 0;
}
on trigger(adc) {
adc.read(#0..#3);
event_count += 1;
event_count_record.fill("EventCount", event_count);
event_count_record.send();
}
fill() メソッドの第3引数にデータ幅(1から32)指定できます.省略した場合は 32 となります.第4引数には kdfdump などのツールで表示したときの表示フォーマットを指定できます.指定形式は C の printf() と同様です.
run_header_record.fill("address", address, 24, "%08x");
データ幅や表示フォーマットの指定は KDF4 以降でのみ利用可能です.それ以外の場合は,この指定は無視されます.
時刻の取得
シーケンスアクション生成関数 readTime() は,シーケンス実行時に時刻を取得し,引数のレジスタにその値を格納します.
Register time, event_number;
DataRecord event_info;
on trigger(adc) {
adc.read(channel_list);
readTime(time);
event_number.add(1);
event_info.fill("time", time);
event_info.fill("event_number", event_number);
event_info.send();
}
readTime() は,第2引数にレジスタを与えれば,そこにマイクロ秒の時間を返します.
Register time_sec, time_usec;
readTime(time_sec, time_usec);
event_info.fill("time_sec", time_sec);
event_info.fill("time_usec", time_usec);
event_info.send();
IntervalTimer や OneShotTimer などのタイマ系ソフトウェアモジュールは,read() シーケンスアクションにより,UNIX 時間をデータとしてストリームに送り出します.
SoftwareModule timer("IntervalTimer");
on trigger(timer) {
timer.read(#0);
adc.blockRead();
}
KiNOKO Version 2.0 からは,TimePacket が導入され,Collector など Kinoko の標準ツールで取得したデータには全て秒精度のタイムスタンプが付加されるようになりました.このタイムスタンプ情報は kdfdump や kdftable などのダンプツールで表示されます.
外部イベントインターフェース
[TinyKinoko, SmallKinoko ではこの機能は利用できません]
KCOM イベントなどの外部イベントに応じてシーケンスを起動するには,on command 文を使用します.on command 文はパラメータを取り,最初のパラメータにイベント名,必要ならそれ以降に引数を指定します.引数は,すでに宣言されたレジスタでなければなりません.
Register threshold;
on command("setThreshold", threshold) {
discriminator.writeRegister(address = 0, threshold);
}
また,invoke 文を使うことにより,KCOM イベントなどの外部イベントを発行することができます.
on trigger(adc) {
adc.read(#0..#3);
Register event_count;
event_count.add(1);
when (event_count > 100) {
invoke clear();
event_count.load(0);
}
}
外部レジストリインターフェース
読み出しスクリプトから KCOM レジストリなどの外部レジストリにアクセスするためのインターフェースとして,getRegistry()/setRegistry() と readRegistry()/writeRegistry() があります.前者は通常の関数で,スクリプト実行時にレジストリにアクセスします.後者はシーケンスアクション生成関数で,実際にレジストリにアクセスするのはシーケンス実行時になります.
スクリプト実行時に変数に読む
string run_type = getRegistry("control/run_type");
if (run_type == "calibration") {
on run_begin {
pulser.start();
}
}
シーケンス実行時にレジスタに読む
on run_begin {
Register threshold;
readRegistry("control/threshold", threshold);
discriminator.setThreshold(threshold);
}
データソースIDとセクションIDの指定
通常,データソース ID や セクション ID は,Kinoko によって自動で割り当てられますが,これらの値がユーザの指定した値に固定されていると解析プログラムなどが作成しやすくなることがあります.
これを行なうために,スクリプト中でこれらの値を指定できるようになっています.
データソース ID を指定するには,datasource エントリのデータソース名の直後で,"<>" で囲ってデータソース ID を記述します.
セクション ID は,そのデータを読み出すモジュールオブジェクトのコンストラクタにおいて,引数によってセクション名とともに指定します.
datasource CamacAdc<3>
{
CamacCrate crate;
CamacController controller("Toyo-CC7x00");
CamacModule adc("Rinei-RPC022", "adc", 7);
crate.installController(controller);
crate.installModule(adc, 2);
on trigger(adc) {
adc.read(#0..#15);
adc.clear();
}
}
特に指定しなければ,Kinoko の自動割り当てによるデータソース ID およびセクション ID の値は 0x4000 (16384) 以上になります.手動による指定では,これらより小さい値を使うようにしてください.また,0 は特別な意味を持つので,使わないようにしてください.
ネストデータセクションと unit 文
通常,一つの読み出しアクションにつき一つのデータセクションが生成されますが,unit 文を使うと,複数の読み出しアクションをまとめて一つの nested セクションを生成することができます.
on trigger(adc) {
unit event {
adc.read(#0..#3);
tdc.read(#0..#3);
}
}
データソースと同様に,セクション名の直後で "<>" で囲むことにより,セクション ID を指定することができます.
unit event<12> {
データソースアトリビュート宣言
attribute 文を使用すると,スクリプトからデータソースアトリビュートを追加することができます.
datasource CamacAdc
{
attribute setup_version = "1.0";
CamacCrate crate;
CamacController controller("Toyo-CC7x00");
CamacModule adc("Rinei-RPC022");
crate.installController(controller);
crate.installModule(adc, 2);
on trigger(adc) {
adc.read(#0..#15);
adc.clear();
}
}
ビュースクリプト
ビュースクリプトは,データの処理手順やヒストグラム等の表示手順などを表現する内部オブジェクトの構造(アナリシスシーケンスとビューシーケンス)を構築するために,KinokoViewer などによって使用されるスクリプトです.
基本スクリプトに加え,以下の文法要素が追加されています.
- display エントリ
- analysis 文
- on 文
- when 文
- invoke / dispatch 文
- DataElement クラス
- Histogram / Histogram2d / Trend / Wave / Map / Tabular / Schematic クラス
- Grid / Placer / Page クラス
- PlainTextViewRepository / XmlViewRepository / RootViewRepository クラス
- setRegistry()/getRegistry() 関数
アナリシスシーケンスとビューシーケンス
ビュースクリプトも読み出しスクリプトと同様にシーケンスの構造を記述するものですが,ビュースクリプトでは,データの処理に関するシーケンス(アナリシスシーケンス)と,表示要素(ビューオブジェクト)に対するシーケンス(ビューシーケンス)の2つを記述します.
アナリシスシーケンスは,対象とするデータを受け取るたびに実行され,ヒストグラムのフィルやデータ条件に基づくユーザへの通知などを行います.
一方,ビューシーケンスは,run_begin/run_end などの特定の条件や外部からのコマンド,あるいはタイマなどにより起動され,ビューオブジェクトの描画やファイルへの保存などを行います.
アナリシスシーケンス
アナリシスシーケンスはキーワード analysis で記述します.アナリシスシーケンスは,処理対象のデータパケットを受け取るたびに実行されます.analysis キーワードの直後に,処理対象データのデータソース名を指定します.
Histogram histogram_adc_01("ADC ch 01", 256, 0, 4096);
analysis ("CamacAdc") {
DataElement adc_01("adc", 1);
histogram_adc_01.fill(adc_01);
}
システムにデータソースが一つしかない場合(SmallKinoko を使っている場合など),以下のように,データソース名を省略することができます.データソースが複数あって,データソース名が省略されている場合,処理対象となるデータソースは未定義です.
Histogram histogram_adc_01("ADC ch 01", 256, 0, 4096);
analysis {
DataElement adc_01("adc", 1);
histogram_adc_01.fill(adc_01);
}
ビューシーケンス
ビューシーケンスは,シーケンス開始条件とともにキーワード on で記述します.シーケンス開始条件には,以下のものがあります.
- on every (time sec)
- time に指定された時間ごとにシーケンスを繰り返し実行する.
- on construct / on destruct
- システム構築直後または終了処理直前にシーケンスを実行する.
- on run_begin / on run_end
- ラン開始直前またはラン終了直後にシーケンスを実行する.
- on run_suspend / on run_resume
- ランが中断した直後または再開する直前にシーケンスを実行する.
- on pre_clear / on post_clear
- ビューアの表示がクリアされる直前または直後にシーケンスを実行する.
以下は,ビューシーケンスの記述例です.
on every(1 sec) {
histogram_adc_01.draw();
}
PlainTextViewRepository repository("foo");
on run_end {
histogram_adc_01.save(repository);
}
DataElement クラス
DataElement クラスは,アナリシスシーケンスにおいて,データストリーム中の特定のデータエレメントを指定するために使われるものです.
Histogram histogram_adc_01("ADC ch 01", 256, 0, 4096);
analysis {
DataElement adc_01("adc", 1);
histogram_adc_01.fill(adc_01);
}
指定するデータセクションの型 (indexed, tagged, nested) に対応して,以下のようにいくつかのコンストラクタがあります.
DataElement adc_01("adc", 1);
DataElement monitor_high("monitor", "high_gain");
DataElement pmtadc_01("pmt:adc", 1);
DataElement adc("adc");
ビューオブジェクト
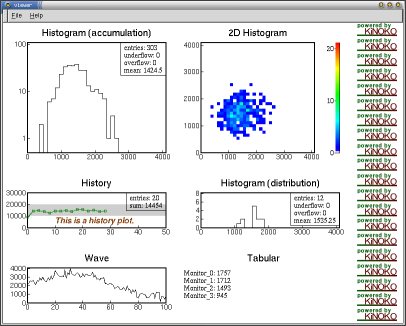
ヒストグラムなど,ビューシステムにおいてデータをある側面から要約し,画面への表示やファイルへの保存などをできるようにしたオブジェクトをビューオブジェクトと呼びます(ただし,画面への表示のみに着目してデータと直接関係しない特殊なビューオブジェクトもあります).以下は,現在 Kinoko で利用できるビューオブジェクトです.
- ヒストグラム (Histogram)
- 普通の1変数のヒストグラム.
- 2元ヒストグラム (Histogram2d)
- 普通の2変数ヒストグラム.Scatter/Color/Box などの形で平面上に描画される.
- トレンド (Trend)
- 値の時間変化に着目したもの.データのタイムスタンプ(時刻情報)をもとに,一定時間間隔ごとのデータ数・和・平均・分散など計算し,表示する.トリガレートなどの統計量や,HV 値や温度などの連続変化量など.
- 波形 (Wave)
- フラッシュADCのデータなど,一つのチャンネル(アドレス)の1イベント分のデータが複数のデータエレメントで構成される場合の,インデクスに対するデータ値の形.フラッシュADCなら波形になる.
- マップ (Map)
- 一つのイベントが複数チャンネルのデータから構成される場合の,各チャンネルのデータの値.指定した位置に,データ値に対応した色の円が描画される.例えば,これを電子回路の各チャンネルの位置に対応するように並べれば,各チャンネルのアクティビティを表示できる.
- 表 (Tabular)
- データのテキスト表示.tagged 形式のデータなど,データ要素に名前が付いていれば,「名前:値」形式で表示される.
- 図 (Schematic)
- イベントビューアのように,データを図形の色やテキストで表現したものを平面上に自由に配置したもの.
- 絵 (Picture)
- データ表示にはかかわらない.固定した文字や図形,イメージなどを表示するためのもの.
これらのビューオブジェクトにデータを読ませるには,アナリシスシーケンスを構築し,そこにデータ読みこみアクションを追加します.上記のビューオブジェクトには,このために以下の2つのアナリシスシーケンスアクション生成メソッドがあります.
- void fill(DataElement data_element)
- 指定されたデータエレメントに対応するデータを読む.
- void fillOne(DataElement data_element)
- ビューオブジェクトが既にデータを保持していなければ,指定されたデータエレメントに対応するデータを 1 イベント分だけ読む.保持しているデータは,それが描画された直後または clear() アクションが実行されたときに開放される.
fill() アクションは,ヒストグラムのように全てのデータを処理したい場合に用います.一方,fillOne() は,イベントビューアのように,毎回1イベントだけを抽出して処理したい場合に使用します.抽出するイベントを選択するには,後述の when 文を使用します.
ビューオブジェクトの種類により,上記のうち一方のみが意味をもつ場合があることに注意してください.例えば,トレンドビューは,データの経時変化に注目しているので,fillOne() は通常意味を持ちません.逆に,表(Tabular)で fill() を行なうと,描画するまでの全てのデータが保持されてしまい,メモリを大量に消費するとともに,描画の際に行があふれてしまいます.
アナリシスシーケンスでデータを読ませたビューオブジェクトは,ビューシーケンスで画面に表示したりファイルに保存したりできます.以下は,上記のビューオブジェクトが共通で持っているビューシーケンスアクション生成メソッドです.
- void draw()
- 保持しているデータを画面に描画する.データを fillOne() で取り込んでいた場合はそれを解放する.
- void clear()
- 保持しているデータを消去する.データを fillOne() で取り込んでいた場合はそれを解放する.
- void save(ViewRepository repository)
- 保持しているデータをリポジトリ(ファイルなど)に保存する.
ほとんどのビューオブジェクトでは,上記のシーケンスアクション生成メソッドに加えて,以下の通常のメソッドが利用できます.
- void setAxisTitle(string x_title, string y_title)
- 軸のタイトルを設定する
- void setYScaleLog() / void setYScaleLinear()
- 縦軸をログスケールやリニアスケールにする
- void setDisplayStatistics(string stat_name, ...)
- プロット右上部の統計窓に表示する統計値を指定する."mean", "entries", "overflow" など.可変個の引数で複数の統計値を指定できる.
- void setColor()
- void setFont()
- void setTextAdjustment()
- 図形要素を描く際のプロパティを設定する
- void putLine(float x0, float y0, float x1, float y1)
- void putRectangle(float x0, float y0, float x1, float y1)
- void putCircle(float x, float y, float radius)
- void putText(float x, float y, string text)
- ビューオブジェクトの表示領域に線分や文字などの図形要素を配置する.座標系はビューオブジェクトの座標(スクリーン座標ではない).円は,座標系の縦横比に応じて,通常は楕円になる.
- void putImage(float x, float y, string file_name)
- ファイルからイメージを読み,ビューの表示領域に配置する.座標系はビューオブジェクトの座標(スクリーン座標ではない).PNG や JPEG をはじめ,ほとんどの画像フォーマットが使用できる.
これらは通常のメソッドのため,スクリプト実行時(システム構築時)に一度しか実行されないことに注意してください.
以下に,各ビューオブジェクトごとの詳細を示します.
ヒストグラム (Histogram)
普通の1変数ヒストグラムです.ファイルなどに保存されている別のヒストグラムを「参照ヒストグラム」として,ノーマライズして重ね書きすることができます.ノーマライズは,ヒストグラムの累積時間が同じになるように行われます.
もし参照ヒストグラムに時間情報が記録されていなければ,ノーマライズはエントリ数が同じになるように行われます(Kinoko Versin 2.1 以前では,常にエントリ数でノーマライズされます).
Histogram histogram("ADC ch 0", 256, 0, 4096);
analysis {
DataElement adc00("adc", 0);
histogram.fill(adc00);
}
on every(1sec) {
histogram.draw();
}
- Histogram(string title, int nbins, float min, float max)
- コンストラクタ.引数でビンの取り方を指定する.
- void setReferenceHistogram(ViewRepository repository, string name, float tolerance_sigmas=3)
- 参照ヒストグラムを設定する.参照ヒストグラムはノーマライズされた上でビンごとに tolerance_sigmas に指定された幅の灰色バンドで重ね書きされる.
ヒストグラムビューでは,fill() と fillOne() の両方を使うことができます.複数チャンネルを持ったデータエレメントで fillOne() を使うと,イベントごとのデータ値の分布図を作ることができます(全チャンネルのイベントごとのヒット時間分布など).
2元ヒストグラム (Histogram2d)
普通の2変数ヒストグラムです.draw() のオプションにより,Color / Scatter / Box などの形式で描画することができます.
Histogram2d histogram("TDC v.s. ADC", 256, 0, 4096, 256, 0, 4096);
analysis {
DataElement adc00("adc", 0);
DataElement tdc00("tdc", 0);
histogram.fill(adc00, tdc00);
}
on every(1 sec) {
histogram.draw();
}
- Histogram2d(string title, int x_nbins, float x_min, float x_max, int y_nbins, float y_min, float y_max)
- コンストラクタ.引数でビンの取り方を指定する.
- void fill(DataElement data_element_x, DataElement data_element_y)
- void fillOne(DataElement data_element_x, DataElement data_element_y)
- データを読みこむアナリシスシーケンスアクション生成メソッド.Histogram2d の fill() のみ引数に DataElement を2つとる.
- void draw(string type = "color")
- 引数 type で描画の形式を指定できる.現在有効な type は以下のとおり.
- color: 色を使って値を表現する.
- scatter: 各ビンで,値に比例した数の点を描く.
- box: 値に比例した面積の長方形を描く.
2元ヒストグラムビューでは,ヒストグラムビューと同様に,fill() と fillOne() の両方を使うことができます.
トレンド (Trend)
値の時間変化を表示するものです.データのタイムスタンプ(時刻情報)をもとに,一定時間間隔ごとのデータ数・和・平均・分散など計算し,表示します.時間軸は,開始からの経過時間と絶対時刻の両方の表示を指定できます.
表示対象の値は draw() で指定します.表示対象の値に対し,「正常範囲」を設定し,表示することができます.また,値が正常範囲を出たときに,アラームを発生させることもできます.
Trend trend("Trigger Rate", 1024, 0, 100);
analysis {
DataElement adc00("adc", 0);
trend.fill(adc00);
}
on run_begin {
trend.setOperationRange(10, 30);
trend.enableAlarm("trigger rate out of range")
}
on every(1 sec) {
trend.drawCounts();
}
- Trend(string title, float min, float max, int depth, int tick_width = 1)
- コンストラクタ.min, max は縦軸の範囲,depth は表示する時間幅(秒),tick_width はトレンド上の一点の時間幅(秒)
- void draw()
- void drawCounts() / void drawSum() / void drawMean() / drawDeviation()
- 指定された統計量のトレンドを描画する.
- void setTimeTick(string format, string unit="", int step=0);
- 時間軸を時刻表示とし,その表示形式を設定する.format は UNIX の date(1) コマンドと同形式,unit と step で間隔を指定する.unit は "sec", "min", "hour" など.
- 例えば,setTimeTick("%H:%M", "min", 10) とすると,10分間隔で hh:mm 形式のラベルが付けられる.
- void setOperationRange(float lower_bound, float upper_bound, int number_of_points_to_judge=2)
- 値の「正常値」の範囲を設定する.この範囲はヒストリプロットに描画され,また,enableAlarm() が設定されている場合,値が正常値から連続してはずれた場合,アラームを発行する.
アラームイベントは,最終点を除くデータ点が number_of_points_to_judge 個連続して範囲内に入っている状態から number_of_points_to_judge 個連続して範囲外に出たときに発行される.この値を適切に設定することにより,正常値外で推移している間にアラームが繰り返し発行されたり,少数点の飛び出しや復帰でアラームが発行されたりすることを防ぐことができる.
- void enableAlarm(string message)
- データ値が setOperationRange() で設定した「正常値」外の値になったときに,アラームイベントを発行するようにする.KCOM フレームワークでは,これは "alarm(string message)" の形の KCOM イベントとなる.この message には,enableAlarm() の引数の message がそのまま渡される.
- void disableAlarm()
- アラームイベントの発行を抑止する.
setTimeTick() で時刻表示を設定しなかった場合,横軸の時間表示は開始からの経過時間を hh:mm'ss の形式で表示します.
setOperationRange(), enableAlarm(), disableAlarm() はビューシーケンスアクションです.ビューシーケンス中で,範囲を変更したり,アラームの設定・解除を行なうことができます.常に同じ値を指定したい場合は on run_begin シーケンスの中で設定してください.
ヒストリビューでは,fillOne() は使用できません.
波形 (Wave)
フラッシュADCのデータなどを波形として表示するものです.fill() の使い方により,単体波形と平均波形のどちらも表示できます.
Wave wave_latched("FADC Waveform (Latched)", 0, 4096, 0, 1024);
Wave wave_averaged("FADC Waveform (Averaged)", 0, 4096, 0, 1024);
analysis {
DataElement fadc00("fadc", 0);
wave_latched.fillOne(fadc00);
wave_averaged.fill(fadc00);
}
on every(3 sec) {
wave_latched.draw();
wave_averaged.draw();
}
on every (10 sec) {
wave_averaged.clear();
}
- Wave(string title, float x0, float x1, float y0, float y1)
- コンストラクタ.x0, x1 は横軸の範囲で,データインデクス値.y0, y1 は縦軸で,データ値.10bit 4ksample の FADC のデータを全て表示するなら,(x0, x1, y0, y1) = (0, 4096, 0, 1024) となる.
ウェーブビューでは,fill() と fillOne() の両方を使うことができます.
clear() せずに新しいデータを fill() すると,保持されるデータは各サンプルごとの平均値となります.すなわち,fillOne() を使うと一つの波形を表示し,fill() を使うと平均化された波形を表示することになります.clear() により平均をリセットできます.
マップ (Map)
多数のチャンネルの値を一括して表示するビューです.各チャンネルに対応した点を平面上に配置し,データ値を色で表現します.
Map map("ADC hit map", 0, 1, 0, 16, 0, 4096);
for (int ch = 0; ch < 16; ch++) {
map.addPoint(ch, 0.5, ch + 0.5);
}
map.setPointSize(3);
analysis {
DataElement adc("adc");
map.fillOne(adc);
}
on every(1 sec) {
map.draw();
}
- Map(string title, float x0, float x1, float y0, float y1, float z0, float z1)
- コンストラクタ.x0, x1, y0, y1 は描画点を指定するための座標系,z0, z1 はデータ値の表示範囲.
- void addPoint(int address, float x, float y)
- データアドレス address のデータを位置 (x, y) に表示するように指定する.
- void setPointSize(float point_radius)
- データを表示する点を描画する大きさを指定する.
マップビューでは,fill() は使用できません.
表 (Tabular)
データ値を直接テキストで表示するビューです.tagged データのようにデータに名前が付いていれば「名前:値」の形式で表示されます.データに表示フォーマットが指定されていれば,そのフォーマットで表示されます.特に,読みだしスクリプトの DataRecord の表示に向いています.
Tabular tabular("Laser Intensity Monitor");
analysis {
DataElement monitor("monitor_adc");
tabular.fillOne(monitor);
}
on every(1 sec) {
tabular.draw();
}
- Tabular(string title, int number_of_columns = 1)
- コンストラクタ.指定したカラム数で領域を分割する.
タブラビューでは,fill() は使用できません.
図 (Schematic)
測定器の構造などの上にデータを描画するビューです.データ値は円などの図形の色としても,テキストとしても表示できます.色表示では,値と色の関係をチャンネルごとに指定できるので,柔軟な表現ができます.
Schematic schematic("Schematic View", 0, 100, 0, 100);
schematic.setColorScale(0, 4096, "rainbow gray");
schematic.putRectangleItem(0, 10, 40, 20, 50);
schematic.putTextItem(0, 5, 80, "ch0: %.1f");
analysys {
schematic.fillOne(adc_all);
}
on every(1 sec) {
schematic.draw();
}
- Schematic(string title, float x0, float x1, float y0, float y1);
- コンストラクタ.x0, x1, y0, y1 は描画点を指定するための座標系.
- void setColorScale(float min, float max, string color_scale_name);
- データ値を色で表示するためのスケールを指定する.
- void putRectangleItem(int address, float left, float top, float right, float bottom);
- データ値を色で表示する矩形を配置する.
- void putCircleItem(int address, float x, float y, float radius);
- データ値を色で表示する円を配置する.
- void putTextItem(int address, float x, float y, string format);
- データ値をテキストで表示する領域を配置する.
スキマティックビューでは,fill() は使用できません.スキマティックビューは,データ表示ではない通常の図形描画(putText(),putCircle() や putImage() など)と組み合わせることにより,より効果的な表示を行うことができます.
絵 (Picture)
ピクチャビューは,表示領域だけを持った特殊なビューオブジェクトで,データをフィルすることはできません.putImage() などで絵や文字を表示することを意図しています.
Picture picture;
picture.putImage(0, 0, "KinokoLogo.png");
on post_clear {
picture.draw();
}
- Picture()
- Picture(string title)
- Picture(string title, float x0, float x1, flaot y0, float y1)
- コンストラクタ.引数で座標系を指定する.省略した場合は,(0, 1, 0, 1) となる.
ピクチャビューはデータを表示しないので,fill() や fillOne() は使用できません.ファイルのイメージを描画する場合,draw() は時間がかかることが多いので,draw() アクションは on every() シーケンスではなく on clear() シーケンスに入れるようにしてください.
レイアウトオブジェクト
ページ内レイアウト
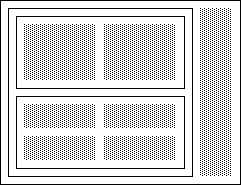
レイアウトオブジェクトは内部に他のビューオブジェクトを格納できる特殊なビューオブジェクトです.それ自身は何も表示しませんが,保持しているビューオブジェクトを自分の領域内に適当に配置して表示されるようにします.配置の仕方により,いくつかの種類のレイアウトオブジェクトがあります.
- グリッド (Grid)
- グリッドは,領域を等間隔の表に区切り,そこにビューを並べていきます.ビューは,グリッドに追加された順で,まず左から右に,次に上から下に,配置されていきます.
- Grid()
- コンストラクタ.表の列数・行数はグリッドオブジェクトによって適当に決定される.
- Grid(int number_of_columns)
- コンストラクタ.引数で表の列数を指定する.行数はグリッドオブジェクトによって適当に決定される.
- void put(View view)
- グリッドにビューを追加する.
- プレーサ (Placer)
- プレーサは,ビューオブジェクトをユーザの指定した位置と大きさで配置します.位置指定に用いる座標系は,横向きが x で右が正,縱向きが y で下が正となります.通常のビューオブジェクトの座標系とは上下が逆になっているので注意してください.
- Placer()
- コンストラクタ.座標系は左上が (0, 0) で右下が (1, 1) となる.
- Placer(double x0, double x1, double y0, double y1)
- コンストラクタ.座標系は左上が (x0, y0) で右下が (x1, y1) となる.
- void put(View view, double x0, double x1, double y0, double y1)
- プレーサ内の指定した位置にビューを配置する.
レイアウトオブジェクト自体もビューオブジェクトなので,レイアウトオブジェクトの中にレイアウトオブジェクトを配置することができます.グリッドとプレーサを組み合わせて使うことにより,複雑なレイアウトを比較的単純に作ることができます.
キャンバスは,ルートグリッドとよばれるグリッドをひとつ持っていて,どのレイアウトオブジェクトにも配置されていないビューオブジェクトを自動的にこのグリッドに配置します.レイアウトオブジェクトを1つ作って全てのビューオブジェクトをこのレイアウトオブジェクトに配置した場合でも,このレイアウトオブジェクト自体はルートグリッドに配置されることになります.
以下はレイアウトオブジェクトを組み合わせて使った例です.ルートグリッドにプレーサを置き,その中にカラム数 1 のグリッドを入れ,さらにその中に 2 つのグリッドを入れています.右端のイメージはプレーサで直接座標を指定しました.
Placer placer(0, 1.2, 0, 1);
Grid grid(1);
Grid grid_upper(2);
Grid grid_lower(2);
placer.put(grid, 0, 1, 0, 1);
grid.put(grid_upper);
grid.put(grid_lower);
grid_upper.put(histogram_adc00);
grid_upper.put(histogram_2d);
grid_lower.put(history_adc01);
grid_lower.put(histogram_adc);
grid_lower.put(wave_fadc00);
grid_lower.put(tabular_adc);
placer.put(picture, 1, 1.2, 0, 1);
複数ページの表示
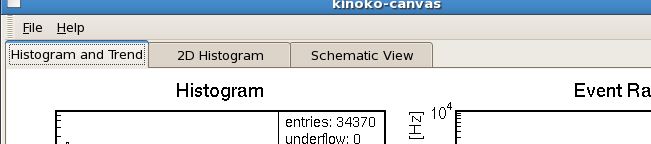
Kinoko Version 2.1 より,ひとつのキャンバスウィンドウで複数のキャンバスを表示できるようになりました.ユーザはウィンドウ上部のタブを使って表示するキャンバスを切替えます.
ページを作成するには,特殊なレイアウトオブジェクトである Page を使用します.
Page page1("Histogram and Trend");
Page page2("2D Histogram");
Page page3("Schematic View");
page1.put(histogram_adc);
page1.put(history_eventrate);
page2.put(histogram_2d);
page3.put(schematic);
ページ内にビューオブジェクトを配置するには,他のレイアウトオブジェクト同様,put() 使用します.ページの中にレイアウトオブジェクトを配置することももちろん可能です.
他のレイアウトオブジェクトと異なり,ページオブジェクトは別のレイアウトオブジェクトの中に配置することはできません.
ビューリポジトリ
ビューリポジトリを使うと,描画したヒストグラムやグラフなどをファイルに保存することができます.保存するファイルフォーマットにより,以下のビューリポジトリがあります.
- PlainTextViewRepository
- 数値をそのままテキストで書き出した型式です.リポジトリごとにディレクトリが作成され,さらにその中に一度の保存で一つのファイルが作成されます.基本的に空白区切りで数字を書き出した型式ですが,パラメータなどはファイルの先頭で「# 名前: 値」の形で記述されます.
- XmlViewRepository (未完成)
- XML 型式で保存します.XML とは,タグにより構造化したテキストの型式です.全てのビューオブジェクトが一つのファイルに保存されます.
- RootViewRepository
- ROOT 型式で保存します.全てのビューオブジェクトが一つのファイルに保存されます.
- RootViewRepository を使用するためには,Kinoko が --with-root オプション付きでコンパイルされている必要があります.
以下は,データ収集中1時間ごとと,データ収集の終了時に,ヒストグラムを ROOT 型式で保存する例です.
display CamacAdc {
Histogram histogram_adc_01("ADC ch 01", 128, 0, 4096);
analysis {
DataElement adc_01("adc", 1);
histogram_adc_01.fill(adc_01);
}
on every (1 sec) {
histogram_adc_01.draw();
}
RootViewRepository repository("histogram_adc01.root");
on every (3600 sec) {
histogram_adc_01.save(repository);
}
on run_end {
histogram_adc_01.save(repository);
}
}
1つのビューオブジェクトを同じリポジトリに何度も保存することができます.
1つのビューオブジェクトが同じリポジトリに2回以上保存されると,最後のもの以外にはリビジョン番号が付加されます.上記の例では,histogram_adc_01;0 histogram_adc_01;1, ... という名前で保存されることになります (リビジョン番号の付け方はリポジトリの種類により変わることがあります).
ビューリポジトリは,大量のデータを高速に保存するのには適していません.データはあくまでデータファイル(データストレージ)に保存し,ビューリポジトリには,興味深いイベントが起きた場合や適当な間隔ごとに絵を保存するなどの目的で使用してください.
外部イベントインターフェース
[TinyKinoko, SmallKinoko ではこの機能は利用できません]
KCOM イベントなどの外部イベントに応じてビューシーケンスを起動するには,on command 文を使用します.on command 文は引数にイベント名をとります.
on command("initialize") {
histogram.clear();
}
また,アナリシスシーケンス中で invoke 文を使うことにより,KCOM イベントなどの外部イベントを発行することができます.
analysis {
DataElement trigger_rate("scaler", 0);
when (trigger_rage > 1000) {
invoke tooHighTriggerRate();
}
}
外部レジストリインターフェース
ビュースクリプトから KCOM レジストリなどの外部レジストリにアクセスするためのインターフェースとして,getRegistry()/setRegistry() 関数があります.これは通常の関数で,スクリプト実行時にレジストリにアクセスします.
double nbins = getRegistry("control/histogram_nbins");
double min = getRegistry("control/histogram_min");
double max = getRegistry("control/histogram_max");
Histogram histogram("histogram", nbins, min, max);
シーケンス実行時にレジストリにアクセスする機能はいまのところ実装されていません.
シーケンスの制御
データエレメントと when 文を組み合わせ,特定のデータ条件についてのみシーケンスを実行させることができます.
analysis {
DataElement adc("adc");
DataElement input_register("input_register");
when (input_register == 0x01) {
histogram.fill(adc);
}
}
データエレメントに対して利用できる関係演算子(データエレメント関係演算子)は以下のとおりです.演算子の意味や結合準位は通常の関係演算子と同じですが,左辺はデータエレメント,右辺は整数値でなければなりません.また,戻り値は特殊な「データエレメント論理値」型となります.この型の値は when 文の条件式でのみ意味を持ちます.
- data_element == value
- データ値が value に等しいとき true を返す.
- data_element != value
- データ値が value に等しくないとき true を返す.
- data_element < valeue
- データ値が value よりも小さいとき true を返す.
- data_element <= value
- データ値が value より小さいか等しいとき true を返す.
- data_element > value
- データ値が value より大きいとき true を返す.
- data_element >= value
- データ値が value より大きいか等しいとき true を返す.
- data_element & value
- データ値と value のビット論理積 (bitwise AND) が 0 でないとき true を返す.
- data_element ^ value
- データ値と value のビット排他的論理和 (bitwise eXclusive OR) が 0 でないとき true を返す.
さらにデータエレメント論理値に対して,以下の論理演算子を利用できます.戻り値はおなじくデータエレメント論理値型です(ネストして使用できます).
- ! data_element_bool
- 論理反転:data_element_bool の値が false のとき true を返す.
- data_element_bool && data_element_bool
- 論理積:右辺値と左辺値がともに true の場合 true を返す.
- data_element_bool || data_element_bool
- 論理和:右辺値と左辺値のどちらかが true の場合 true を返す.
また,アナリシスシーケンス中で dispatch 文を使うことにより,データ条件にもとづいて on command 形式のビューシーケンスを実行することができます.
analysis {
DataElement adc("adc");
DataElement input_register("input_register");
when (input_register == 0x01) {
histogram.fill(adc);
}
when (input_register == 0x02) {
dispatch clear();
}
}
on command("clear") {
histogram.clear();
}
コントロールパネルスクリプト
コントロールパネルスクリプト(KCML スクリプト)は,ユーザのコントロールをシステムに伝達するためのインターフェースであるコントロールパネルの構成を記述するためのスクリプトです.コントロールパネルには,ウィジェットとよばれる部品を配置することができます.ウィジェットには,入力フィールドやチェックボタンなどの入力ウィジェット,ボタンなどのアクションウィジェット,そしてフレームやスペーサなどのレイアウトウィジェットなどがあります.
入力ウィジェットには名前が付けられ,その名前によってウィジェットの値がシステムの他の部分から参照できるようになります.また,アクションウィジェットは,ユーザの操作によって,システムへイベントを発行したり,コントロールパネルスクリプト中に記述されたアクションを実行したりすることができます.
コントロールパネルスクリプトは,Kinoko の他のスクリプトと異なり,XML を用います.<Script> タグを用いると,その中に Kinoko の基本スクリプトを埋め込むことができます.コントロールパネルスクリプトの構造は HTML のフォーム + JavaScript に似ています.
簡単な例
独立アプリケーション
まずはデータ収集システムとは関係のない簡単なアプリケーションを作成して,コントロールパネルスクリプトの概要を見てみます.左側の行番号は説明のためのものなので,入力しないでください.
1: <?xml version="1.0"?>
2:
3: <KinokoControlPanel label="The Graphical Unix Shell">
4:
5: <Label label="command:"/>
6: <Entry name="command"/>
7: <Button label="execute" on_click="execute_command"/>
8:
9: <Script>
10: <![CDATA[
11: void execute_command() {
12: string command = <command>.getValue();
13: println("> " + command);
14: system(command);
15: }
16: ]]>
17: </Script>
18:
19: </KinokoControlPanel>
1行目は,このファイルが XML 形式であることを宣言するための XML の文法です.KCML スクリプトは全体を <KinokoControlPanel> で囲みます(3行目と19行目).5行目から7行目はウィジェット,<Script> タグで囲まれた9行目から17行目は標準 Kinoko スクリプトの埋め込みです.10行目と16行目はその中身の Kinoko スクリプトが XML 文書として解釈されないようにするための XML の文法です.12 行目では特殊な文法が使われていますが,このように <> で囲むことにより,埋め込みスクリプトからウィジェットを参照することができます.
このスクリプトは,標準ユーティリティ kcmlcheck で実行することができます.
% kcmlcheck GraphicalUnixShell.kcml
実行すると,以下のようなウィンドウが表示されます.入力フィールドに任意の UNIX コマンドを書いて,execute ボタンを押すと,それが実行されます.終了するには,メニューから File > eXit を選んでください.
KCOM コントロールパネル
次に,簡単な KCOM を作成して,コントロールパネルを接続してみます.この例では,コントローラコンポーネントとロガーコンポーネントを使って,コントロールパネルからログを書いてみます.コントロールパネルは以下のようになります.
このコントロールパネルの KCML スクリプトは以下のようになります(ファイルが kinoko/local/tutorial/ControlPanel にあります).
<?xml version="1.0"?>
<KinokoControlPanel label="SmallLogger">
<Label label="message:"/>
<Entry name="message" width="256"/>
<VSpace/>
<ButtonList>
<Button name="write" label="Write" tip="click this to write the message"/>
<Button name="quit" label="Quit" tip="click this to quit the system"/>
</ButtonList>
</KinokoControlPanel>
この例では,Button に on_click を指定していないことに注意してください.これにより,ボタンのアクションが KCOM に伝達されるようになります.
KCOM 側では,コントローラとロガーの二つのコンポーネントを起動し,コントローラからのアクション(KCOM イベント)を受け取るようにします.
// SmallLogger.kcom //
import KinokoController;
import KinokoLogger;
execute("kinoko-control --client localhost 10000");
execute("kinoko-board --client localhost 10001");
component KinokoController controller("localhost", "port:10000");
component KinokoLogger logger("localhost", "port:10001");
on startup()
{
controller.open("SmallLogger.kcml");
}
on controller.write()
{
string message = getRegistry("control/message");
logger.writeNotice(message);
}
on controller.quit()
{
controller.quit();
logger.quit();
exit;
}
コントロールパネルスクリプトのボタンの名前が KCOM の on ハンドラで指定されています.この例のように,コントロールパネルの値はレジストリを経由して取得できます.
この KCOM スクリプトは kinoko コマンドにより実行できます.
% kinoko SmallLogger.kcom
KCOM システムインターフェース
KCOM システムへコマンドを送るコンポーネントである KinokoController コンポーネントは,シェルとして通常 kinoko-control を接続します.kinoko-control は,コントロールパネルスクリプト(KCMLスクリプト)を読み,スクリーンにコントロールパネルを描画し,ユーザの入力を待ちます.
ローカルアクション(埋め込みスクリプト関数の呼び出し)に結びつけられていないボタンがクリックされると,kinoko-control は,そのときの入力ウィジェットの値全てとクリックされたボタンの名前(name 属性の値)を KinokoController へ通知します.KinokoController は,入力ウィジェットの値をレジストリ(/control 以下)に記録し,ボタンの名前をそのまま KCOM のイベント名として KCOM イベントを発行します.このイベントにより KCOM スクリプト(後述)の on controller.XXX() が呼び出されます.入力フィールドの値が全てレジストリに記録されているので,KCOM システム内の全てのコンポーネントは getRegistry("control/field_name") によりコントロールパネルの入力フィールドの値を取得することができます.
以下は,SmallKinoko で使われている KCML スクリプトと KCOM スクリプトからの抜粋です.ここでは,コントロールパネルの [construct] ボタンが押されたら,KCOM の on controller.construct() が呼ばれるようになっており,その中でコントロールパネルの入力フィールドに記述されている読み出しスクリプトやビュースクリプトのファイル名やデータファイル名をレジストリから取得するようになっています.
[KCML スクリプト]
<EntryList>
<Entry name="readout_script" label="ReadoutScript (.kts)" option="file_select"/>
<Entry name="view_script" label="ViewScript (.kvs)" option="file_select"/>
<Entry name="data_file" label="DataFile (.kdf)" option="file_select"/>
</EntryList>
<VSpace/>
<Frame name="run_control" label="Run Control">
<ButtonList>
<Button name="construct" label="Construct" enabled_on="stream_ready system_ready"/>
<Button name="start" label="Start" enabled_on="system_ready"/>
<Button name="stop" label="Stop" enabled_on="data_taking"/>
<Button name="clear" label="Clear" enabled_on="system_ready data_taking"/>
<Button name="quit" label="Quit" enabled_on="stream_ready system_ready error"/>
</ButtonList>
</Frame>
[KCOM スクリプト]
on controller.construct()
{
controller.changeState("constructing");
(中略)
string readout_script = getRegistry("control/readout_script");
string view_script = getRegistry("control/view_script");
string data_file = getRegistry("control/data_file");
(中略)
collector.setReadoutScript(readout_script);
viewer.setViewScript(view_script);
recorder.setDataFile(data_file);
(中略)
controller.changeState("stream_ready");
}
コントロールパネルはステートをもっており,これは KCOM の changeState() で設定されます.KCML のボタンウィジェットで enabled_on 属性を指定することにより,そのボタンを操作できるステートを指定できます.この仕組みにより,システムの状況に応じて適正な操作のみをユーザが操作可能なようにすることができます.
入力ウィジェット
現在のところ,以下の入力ウィジェットがあります.これらの値は,ボタンが押されたときに,KinokoController コンポーネントを介してレジストリに記録さます.また,埋め込みスクリプトから getValue() や setValue() を使って値の参照や変更ができます.
エントリ (<Entry>)
テキスト入力フィールドです.以下の属性値を指定できます.
- name (必須): 値を取得するときにキーとなる名前
- label: エントリフィールドの横に描かれる文字列
- selection: 空白区切りで選択可能な値を並べる.これを指定するとプルダウンメニューになる
- width: 入力フィールドの表示幅
- alignment: 内部の文字列の配置.right または left
- on_focus: このエントリがフォーカスされたときに呼び出す埋め込みスクリプトの関数名
- on_blur: このエントリがフォーカスからはずれたときに呼び出す埋め込みスクリプトの関数名
スクリプトから "selection" を setAttibute() することにより,プルダウンメニューの中身を動的に変更することができます.
<?xml version="1.0"?>
<Label label="Input Device"/>
<Entry name="input"/>
<Script>
<![CDATA[
<input>.setAttribute("selection", "ADC1 ADC2 TDC");
]]>
</Script>
</KinokoControlPanel>
チェックボタン (<CheckButton>)
項目選択のためのチェックボタンです.選択されている場合は値 1 を,されていない場合は値 0 をとります.以下の属性値を指定できます.
テキスト入力フィールドです.以下の属性値を指定できます.
- name (必須): 値を取得するときにキーとなる名前
- label: チェックボタンの横に描かれる文字列
ラジオボタン (<RadioButton>)
項目選択のためのラジオボタンです.選択されている場合は値 1 を,されていない場合は値 0 をとります.通常,後述の RadioButtonList によりグループ化し,その中のひとつだけが選択可能なようにします.
以下の属性値を指定できます.
- name (必須): 値を取得するときにキーとなる名前
- label: ラジオボタンの横に描かれる文字列
定数 (<Constant>)
画面には何も表示されませんが,定数値を保持するウィジェットです.KCML スクリプトの中で値をハードコーディングしたい場合に用います.
以下の属性値を指定できます.
- name (必須): 値を取得するときにキーとなる名前
- value (必須): 値
表示ウィジェット
表示ウィジェットは,値の入力にはかかわりませんが,画面上に文字や絵を表示するウィジェットです.通常定数値ですが,埋め込みスクリプトの setValue() メソッドによりその表示内容を変えることもできます.
ラベル (<Label>)
文字列を表示します.
以下の属性値を指定できます.
- name: 埋め込みスクリプトなどから参照するための名前
- label: 表示する文字列
- font: 表示に使用するフォント
- fontsize: フォントサイズ
イメージ (<Image>)
ファイルから画像を読み表示します.PNG や JPEG をはじめ,ほとんどの画像フォーマットが扱えます.
以下の属性値を指定できます.
アクションウィジェット
アクションウィジェットは,クリックなどにより KinokoController コンポーネントを介して KCOM へイベントを送り出したり,埋め込みスクリプトの関数を呼び出したりするウィジェットです.on_click 属性が指定されていれば埋め込みスクリプトを実行し,なければ KinokoController へアクションを送り出します.
ボタン (<Button>)
ボタンです.クリックによりアクションを実行します.
以下の属性値を指定できます.
- name: クリックにより発生させるアクション名(KCOM イベント名)
- label: ボタン上に表示する文字列
- image: ボタン上に表示する画像のファイル名.
- tip: ツールチップに表示させる文字列
- enabled_on: ボタンを使用可能にするステートのリスト.空白区切りで指定する
- on_click: クリックにより実行する埋め込みスクリプトの関数名
レイアウトウィジェット
レイアウトウィジェットは,それ自体は画面に表示されないが,他のウィジェットの並びなどを制御するウィジェットです.レイアウトウィジェットによる指定がない限り,ウィジェットは左から右へ左詰めで並べられていきます.
改行 (<NewLine>)
次のウィジェットが一段下の左端に置かれるようにします
スペーサ (<HSpace> / <VSpace>)
HSpace は横方向,VSpace は縦方向のスペースを挿入します.HSpace は余ったスペースを埋めるように横へ伸びるので,HSpace の右に置かれたウィジェットは右詰めに,HSPace で挟まれたウィジェットは中央揃えで配置されるようになります.
ボックス (<Box>)
複数のウィジェットをまとめてひとつのウィジェットとしてレイアウトされるようにします.スペーサと併用すると便利です.
フレーム (<Frame>)
複数のウィジェットを線で囲みラベルを付けます.
以下の属性値を指定できます.
リスト (<ButtonList> / <RadioButtonList> / <CheckButtonList> / <EntryList>)
複数の同種ウィジェットを一列に整列させて表示します.ButtonList はボタンを横揃えで同じ大きさに並べます.その他は縦揃えで並べます.
テーブル (<Table> / <Cell>)
Table は Cell でまとめられたウィジェットを縦横に揃えた表に配置します.
Table では以下の属性値を指定できます.
- width: 横方向のセルの数
- height: 縦方向のセルの数.足りない場合は自動延長される
- homogeneous: "true" を指定するとセルの幅を揃えて配置する
Cell では以下の属性値を指定できます.
- top: テーブルの中のセルの縦方向座標
- left: テーブルの中のセルの横方向座標
- width: テーブルの中で使う横方向のセル数
- height: テーブルの中で使う縦方向のセル数
ノートブック (<Notebook> / <Page>)
タブのついた複数のパネル(ページ)を作成します.
Notebook では,getValue() / setValue() により表示ページの取得や設定ができます.Notebook では以下の属性値を指定できます.
- name: 埋め込みスクリプトなどから参照するための名前
- tab: タブを表示させる位置:top, bottom, left, right, none
Page では以下の属性値を指定できます.
ツールバー (<Toolbar>)
ツールバーを作成します.ツールバーの中には Button と HSpace を配置できます.
メニュー
<Menu> タグを利用することにより,KCML コントロールパネルのメニューバーに新しいメニューを追加することができます.メニューの中には <MenuItem> でメニュー項目を並べます.MenuItem の振舞は Button と基本的に同等です.
Menu では以下の属性値を指定できます.
- label (必須): メニューに表示させる文字列
MenuItem では以下の属性値を指定できます.
- name: クリックにより発生させるアクション名(KCOM イベント名)
- label: ボタン上に表示する文字列
- enabled_on: メニュー項目を使用可能にするステートのリスト.空白区切りで指定する
- on_click: クリックにより実行する埋め込みスクリプトの関数名
埋め込み Kinoko スクリプト
KCML の中で <Script> タグを使うことにより,Kinoko の基本スクリプトを記述することができます.この中の関数を on_click などにより呼び出すことができ,また,このスクリプト中からウィジェットの値を操作できます.KCML 埋め込みスクリプト (KCMS; Kinoko Control-panel Manipulation Script) では,基本スクリプトに加え,以下の文法要素が追加されています.
- ControlWidget クラス
- lookupWidget() 関数
- saveWidgetValues() / loadWidgetValues() 関数
- currentState() 関数
- <> 演算子
- on 文
- after 文
- invoke 文
ボタンウィジェットなどの on_click 属性,エントリウィジェットなどの on_focus および on_blur 属性に KCMS の関数名を指定しておけば,それらのウィジェットの対応する操作が行われたときに指定した関数が呼び出されます.
KCMS スクリプト中では,lookupWidget() 関数によりウィジェットをオブジェクトとして参照できます.lookupWidget() の引数には,ウィジェットの name 属性の値を指定します.
- ControlWidget lookupWidget(string widget_name)
lookupWidget() により取得したウィジェットオブジェクトに対して,以下の操作ができます.
- getValue()
- ウィジェットの値を参照する.入力ウィジェットでは入力値,その他はウィジェットによって異なる
- setValue()
- ウィジェットに値を設定する.
- enable()
- ウィジェットを操作可能に設定する
- disable()
- ウィジェットを操作不可能に設定する
- getAttribute()
- ウィジェットの属性値を取得する.ただし,取得できる属性値はウィジェットにより異なる
- setAttribute()
- ウィジェットの属性値を設定する.ただし,設定できる属性値はウィジェットにより異なる
<> 演算子は lookupWidget() 関数のショートカットです.lookupWidget(name) と <name> は厳密に同等です.
saveWidgetValue() / loadWidgetValue() 関数により,現在のウィジェット値をファイルに保存したりファイルから読み出して各ウィジェットに設定したりできます.
- void saveWidgetValues(string file_name);
- void loadWidgetValues(string file_name);
ファイル名は任意ですが,普通は拡張子に .kcv (Kinoko Control Values) を用います.ファイル形式は XML です.
invoke 文により,KCMS スクリプトから KinokoController を経由して KCOM イベントを発行することができます.
void start() {
println("start at: " + localTime();
invoke start();
}
on 文により,一定のタイミングで文を実行したり,ステートの変化や KCOM イベントの発行をトラップできます.
- on startup { 文リスト }
- on shutdown { 文リスト }
- 開始時および終了時に呼び出される
- on every (TIME) { 文リスト }
- TIME に指定した時間間隔で呼び出される.TIME の形式は 「数値 単位」 で,単位には sec min hour day のいずれかを指定する
- on transition(from FROM to TO) { 文リスト }
- on transition(from FROM) { 文リスト }
- on transition(to TO) { 文リスト }
- on transition() { 文リスト }
- 指定したステートの変化で呼び出される.from や to は省略でき,その場合は全てのステートが指定されたのと同等になる
- on invocation(NAME) { 文リスト }
- on invocation() { 文リスト }
- 指定の KCOM イベントが発行されたときに呼び出される
on transition でトリガされるステート変化は,KCOM スクリプト中で changeState() を呼び出すことにより引き起こされます.つまり,コントロールパネルのステートとステート遷移は,KCOM スクリプトによって定義されているということです.
SmallKinoko.kcom には,以下のステートが定義されています.
- component_ready: 各コンポーネントの起動ができた状態.接続を行い,stream_ready に遷移する.
- stream_ready:コンポーネントの接続ができた状態.[Construct] と [Quit] ができる.
- constructing:[Construct] をしている途中の状態.完了して system_ready に遷移する.
- system_ready:データをとる準備ができた状態.[Construct],[Start],[Quit] ができる.
- data_taking:データをとっている状態.[Stop] ができる.
- stopping:データ収集の終了処理をしている状態.完了して system_ready に遷移する.
- shutdown:[Quit] 後の状態.
- error:エラーが起き,処理を進められない状態.[Quit] しかできない.
after 文により,指定の時間の遅延の後で関数または KCOM イベントの発行を行うように指定できます.構文は以下のとおりです.
- after (TIME) call 関数;
- after (TIME) invoke イベント;
TIME の時間指定形式は on 文と同様です.
on transition(to "running") {
after (10 min) call stop();
}
currentState() 関数により,現在のステートを取得できます.
ビジュアルウィジェットとビューレット
ビジュアルウィジェットは,グラフィクスを使って値をより視覚的に表示するもので,Label などにより数値のみを表示するよりもかなり表現力があります.ビューレットはビューアウィンドウ中で描画されていたプロットなどをコントロールパネル上に表示するウィジェットです.
現在のところ,ビジュアルウィジェットもビューレットも, Web-KiNOKO によるブラウザ上での表示には対応していません.
(<VisualDisplay>)
(<VisualLight>)
(<VisualIndicator>)
(<VisualGuage>)
(<VisualMeter>)
(<VisualButton>)
(<VisualLightButton>)
(<VisualSlider>)
(<Canvas>)
(<Plot>)
コンポーネント配置結合スクリプト
[TinyKinoko, SmallKinoko のみを使う場合はこの章は読み飛ばして構いません]
コンポーネント配置結合スクリプト(KCOMスクリプト)は,システムを構成する各コンポーネントの計算機への配置や,コンポーネントイベント/スロットの結合,共有オブジェクトの割り付けなどを記述するために,Kinoko のシステムプロセス(kcom-manager)によって使用されるスクリプトです.KCOM スクリプトでは,基本スクリプトに加えて,以下の文法要素が追加されています.
- import 文
- component 文
- assign 文
- asynchronous 文
- after 文
- exit 文
- on エントリ
- setTimeout() / enableTimeout() / disableTimeout() 関数
- setRegistry() / getRegistry() 関数
KCOM スクリプトは読み出しスクリプトやビューオブジェクトとは異なり,普通のインタプリタとして動作します(シーケンスは使用しません).すなわち,全ての変数や式は,実行時に毎回値が評価されるということです.
KCOM スクリプトにより,以下のようなことができます.
- コンポーネントを指定した計算機上で実行させる.
- コンポーネントのプライベート入出力チャネルを端末ウィンドウやソケットに結合させる.
- コンポーネント内部の公開オブジェクトを別のコンポーネントと共有させる.
- コンポーネントに対しイベントを発行する(イベントスロットを実行させる).
- コンポーネントが発行するイベントを取得し,それに対して処理を行なう.
- コンポーネントのプロパティ値を取得する.
- レジストリの値を取得・変更する.
もちろん,Kinoko の基本スクリプトが持つ機能も全て利用できます(データベースアクセスなど).また,コンポーネントの入出力チャネルに接続させる KinokoShell のプロセス(キャンバスやコントロールパネルなど)の実行も通常 KCOM スクリプト中から行ないます.
KCOM スクリプトの大まかな構造は以下のようになります.
import コンポーネント型名;
component コンポーネント型名 コンポーネント名("ホスト名", "入出力チャネル");
assign コンポーネント名.オブジェクト名 => コンポーネント名.オブジェクト名;
on startup()
{
}
on shutdown()
{
}
on コンポーネント名.イベント名(イベント引数)
{
コンポーネント名.イベント名(イベント引数);
}
簡単な例
完全に動作する簡単な例がコントロールパネルスクリプトの章にすでに出ています.ファイルは kinoko/local/tutorial/ControlPanel にあります.
// SmallLogger.kcom //
import KinokoController;
import KinokoLogger;
execute("kinoko-control --client localhost 10000");
execute("kinoko-board --client localhost 10001");
component KinokoController controller("localhost", "port:10000");
component KinokoLogger logger("localhost", "port:10001");
on startup()
{
controller.open("SmallLogger.kcml");
}
on controller.write()
{
string message = getRegistry("control/message");
logger.writeNotice(message);
}
on controller.quit()
{
controller.quit();
logger.quit();
exit;
}
この KCOM スクリプトは kinoko コマンドにより実行できます.
% kinoko SmallLogger.kcom
コンポーネントのインターフェース宣言
各コンポーネントのインターフェース定義は,コンポーネントのプログラムを単体で引数なしで実行することにより見ることができます.以下は,Kinoko のデータ読み出しコンポーネントである KinokoCollector のインターフェース定義を表示させたものです.
% KinokoCollector-kcom
//
// KinokoCollectorCom.kidl
//
// Kinoko Data-Stream Component
// Collector: DAQ front-end process
//
// Author: Enomoto Sanshiro
// Date: 22 January 2002
// Version: 1.0
component KinokoCollectorCom {
property string host;
property string stream_type;
property string state;
property int port_number;
uses KinokoLogger logger;
emits dataAcquisitionFinished();
accepts setSource();
accepts setSink();
accepts setSourceSink();
accepts connect();
accepts construct();
accepts destruct();
accepts disconnect();
accepts halt();
accepts quit();
accepts start();
accepts stop();
accepts setReadoutScript(string file_name, string datasource_name);
accepts setMaxEventCounts(int number_of_events);
accepts setRunLength(int run_length_sec);
accepts executeCommand(string command_name, int parameter);
accepts disable();
}
%
ここで,emits はこのコンポーネントが発行するイベントを,accepts はこのコンポーネントが受け取ることのできるイベントを,それぞれ宣言しています.また,property は外部から参照できるパラメータ(プロパティ)を宣言しています.uses はこのコンポーネントが必要とする外部オブジェクトで,システムを構成するコンポーネントのいずれかにより提供されなければなりません.この例では KinokoLogger というクラスのオブジェクトを必要としています.
Kinoko の標準コンポーネントのうち,KinokoLogger クラスのオブジェクトを提供するのは KinokoLogger コンポーネントです.以下は KinokoLogger コンポーネントのインターフェース定義を表示させたもので,この中で provides によって,KinokoLogger クラスのオブジェクト logger を,他のコンポーネントから参照できる公開オブジェクトと宣言しています.
% KinokoLogger-kcom
//
// KinokoLoggerCom.kidl
//
// Kinoko System Component
// Logger: Logbook Writer
//
// Author: Enomoto Sanshiro
// Date: 22 January 2002
// Version: 1.0
component KinokoLoggerCom {
property string host;
provides KinokoLogger logger;
emits processRemarkable(string message);
emits processWarning(string message);
emits processError(string message);
emits processPanic(string message);
accepts quit();
accepts startLogging(string file_name);
accepts writeDebug(string message);
accepts writeNotice(string message);
accepts writeRemarkable(string message);
accepts writeWarning(string message);
accepts writeError(string message);
accepts writePanic(string message);
}
%
KCOM スクリプトの先頭では,import 文によってこのコンポーネント宣言を取り込み,KCOM スクリプト内でコンポーネントとして使用できるようにします(が今のところ何もしていません).
上記の Collector および Logger コンポーネントを使用するためには,以下のように記述します.
import KinokoCollector;
import KinokoLogger;
コンポーネントの宣言と配置
import により KCOM スクリプトからコンポーネントを使えるようにした後は,component 宣言によりそれらのコンポーネントを計算機上に実際に配置します.また,このコンポーネントを KinokoShell に接続する場合には,同時に KinokoShell の接続先も指定します.以下は,Collector と Logger をそれぞれ host_daq と host_hub に配置し,Logger コンポーネントのプライベート入出力チャネルを KinokoShell である kinoko-board にソケット経由で接続した例です.kinoko-board への接続を指定する前に,execute() 関数により kinoko-board プログラムを起動しておきます.
string host_daq = "daq.kinoko.ac.jp";
string host_hub = "hub.kinoko.ac.jp";
int port_log = 30000;
execute("kinoko-board", "--client", host_hub, port_log);
component KinokoCollector collector(host_daq);
component KinokoLogger logger(host_hub, "port: " + port_log);
オブジェクトの結合
次に,assign 文により,logger コンポーネントがエクスポートしている logger オブジェクトを Collector コンポーネントにインポートします.
assign logger.logger => collector.logger;
ただし,この例に限っては,collector コンポーネントが Logger 型のオブジェクトを必要としており,Logger 型オブジェクトを提供するコンポーネントが KCOM システム上にひとつしか存在していないので,上記の結合は自動で行われ,明示的に書く必要はありません.Logger 型オブジェクトをエクスポートするコンポーネントが複数存在する場合は,assign 文を使って明示的に指定する必要があります,
イベントとスロットの結合
コンポーネントが emit したイベントは,KCOM スクリプトの on 文で受け取ることができます.on 文には,特定のコンポーネントからの特定のイベントだけを受け取る on ComponentName.EventName(...) {} 形式と,発行コンポーネントによらずイベント名だけを指定する on .EventName(...) {} 形式があります.
以下は,Recorder 型の recorder コンポーネントが発行する finishRecording() イベントだけを受け取る例です.
on recorder.finishRecording() {
// データの記録が完了したのでここで終了処理を開始する
}
以下は,processError(string message) イベントを,発行元にかかわらず受け取る例です.
on .processError(string message) {
println("ERROR: ", message);
// エラー処理をする
}
on 文の後ろの {} の中に,イベントを受け取ったときの処理を書きます.この中で他のコンポーネントのイベントスロットにイベントを送ることができるので,これによりコンポーネント間でイベントとスロットを間接的に接続することができます.以下は,controller コンポーネントの start() イベントを,collector コンポーネントの start() イベントに間接的に接続した例です.{} の中には複数の文をかけるので,同時に reporter コンポーネントにも write() イベントを送っています.
on controller.start() {
collector.start();
reporter.write("start_time", localTime());
}
ここで,collector コンポーネントは start() イベントを,reporter コンポーネントは write(string, string) イベントを,それぞれ accept できる必要があります.
プロパティの参照
コンポーネントのプロパティは,オブジェクトと同じ形式で,ドット演算子.を使って読み出すことができます.ただし,変更はできません.コンポーネントのプロパティ値を変更した場合は,イベントを経由して行うようにしてください.
on .stop() {
string collector_state = collector.state;
if (collector_state != "running") {
println("The collector component is not running");
return;
}
レジストリの参照
レジストリはひとつの KCOM システム全体で共有されるパラメータの集合です.ツリー構造で管理され,パラメータ名はツリーにそって / で区切ったものになります(UNIX のファイル名と同じ構造).このレジストリ値は読みだしスクリプト,ビュースクリプトおよびコントロールパネルスクリプトからもアクセスでき,設定値などを共有するために使われます.
KCOM スクリプトからレジストリ値にアクセスするには,getRegistry() / setRegistry() 関数を使うだけです.それぞれ,以下のような定義になっています.
- string getRegistry(string name)
- void setRegistry(string name, string value)
oneway 呼び出し,非同期実行とタイムアウト
KCOM スクリプトからコンポーネントにイベントを投げた場合,KCOMスクリプトの実行はコンポーネントがイベントの処理を終了するまで停止します(同期実行).一部のコンポーネントの不具合により,システム全体が停止するのを防ぐために,コンポーネントからの返信待ちにタイムアウトを設定できます.
- void setTimeout(int length_sec)
- コンポーネントへイベントを送ってからの返信待ち時間の上限を設定する
- void enableTimeout()
- タイムアウト処理を行う
- void disableTimeout()
- タイムアウト処理を行わない
もし設定した時間を経過してもコンポーネントからの返信がない場合,そのコンポーネントは正常な動作をしてないと判断し,システムから切り離されます(画面には component XXX dismissed と表示されます).切り離されると,それ以降のそのコンポーネントへのアクセスは全てスキップされます.
ユーザからの入力を受け取るイベントなど,イベントの種類によっては返信までに大きく時間がかかるものもあります.そのようなものがタイムアウトで切り離されないようにするために,返信までタイムアウト以上の時間がかかるイベントを投げるときには,disableTimeout() により一時的にタイムアウト処理を止めるようにしてください.
disableTimeout();
// ポップアップウィンドウを開くので,返信まで時間がかかる //
string decision = controller.openQueryPopup(
"Warning", "Yes No",
"file exists: " + data_file + " -- overwrite?"
);
enableTimeout();
場合によっては,イベントごとに同期を取る必要がないこともあります.このようなときは,同期をとらなくて良い処理をまとめて実行することにより,システムの処理性能を大幅に向上させることができます.KCOM スクリプトでは,asynchronous 文により,非同期に同時実行できるイベントをまとめることができます.
asynchronous {
collector.construct();
analyzer.construct();
recorder.construct();
viewer.construct();
}
asynchronous ブロックに入ると,リプライを待たずに次々とイベントを発行します.最後に,全てのイベントの処理が終わるのを待って,asynchronous ブロックが終了します.
さらに,イベントの種類によっては,そもそもリプライを待つ必要が全くないものもあります.このようなときは oneway 文によりリプライ不要と宣言することによって,システムの効率を大きく向上させることができます.
oneway {
reporter.write("run-name", run_name);
reporter.write("comment", comment);
reporter.write("date", localTime());
reporter.write("log-file", log_file_name);
reporter.write("buffer-size", buffer_size);
reporter.write("data-file", data_file);
reporter.write("script", readout_script, "target=collector", "type=kts");
reporter.write("script", view_script, "target=viewer", "type=kvs");
}
この例では,他のコンポーネントは reporter の処理を待つ必要が全くないので,oneway によりリクエストだけ出しておいて先に進むようにしています.
実行タイミングの制御
KCOM の on 文では,KCOM イベント取得時での呼び出しに加えて,特定のタイミングで文を実行させるように指定することもできます.
on startup() {
}
on shutdown() {
}
on every(10 sec) {
}
on every() の括弧内には時間を単位付きで指定します.単位には,sec min hour day が使用できます.
また,after 文を使うことにより,指定した時間の経過後に指定の関数を呼び出すことができます.
on startup() {
after (1 hour) call suggestFinish();
println("Let's finish in one hour.");
}
void suggestFinish() {
println("It's about time to finish.");
}
after () call ... の括弧内には時間を単位付きで指定します.単位には,sec min hour day が使用できます.
指定時間に達するまでの間は,通常の KCOM 処理が行われます.
システムの終了
KCOM システムは,exit 文に達することにより終了します.
on controller.quit() {
exit;
}
SmallKinoko の構造と拡張方法
[TinyKinoko, SmallKinoko のみを使う場合はこの章は読み飛ばして構いません]
SmallKinoko は,ひとつの PC 上でひとつの Collector コンポーネントを使用する構成を仮定して書かれた KCOM と KCML のセットです.どちらも,kinoko/scripts にあり,ファイル名は SmallKinoko.kcom と SmallKinoko.kcml です.Kinoko と SmallKinoko の違いは自分で作った KCOM を使うかどうかだけで,SmallKinoko を起動することと,SmallKinoko.kcom を指定して Kinoko を起動することは同等です.
% kinoko $KINOKO_ROOT/scripts/SmallKinoko.kcom
したがって,独自の分散並列システムを構築する場合でも,SmallKinoko.kcom をもとにすると作成が容易になります(現時点ではデータストリームの接続が手作業でかなり煩わしくなっていますが,このへんは将来改良予定です).
SmallKinoko の構造
SmallKinoko には Collector,Recorder,Viewer がひとつづつあり,これらが Buffer を介して接続されています.さらに Collector と Buffer の間には何もしない Transporter コンポーネントが analyzer という名前で挿入されており,これをこれを独自のデータアナライザコンポーネントに置き換えることにより,容易に自分のコンポーネントを組み込めるようになっています(1行の変更).また,Collector が Buffer に直接接続されていないことにより,Collector だけを別 PC 上で走らせるという変更も極めて容易です(これも1行の変更).SmallKinoko には,これらデータストリームコンポーネントに加えて,ユーザ操作を KCOM に伝達する Controller,ログを記録する Logger およびパラメータを保存してランサマリを生成する Reporter の各コンポーネントがひとつづつ配置されています.
Recorder が生成するデータファイル(KDFファイル)に加えて,SmallKinoko はいろいろなファイルを生成します.Logger,Reporter および KinokoCanvas は,それぞれログメッセージ,ランパラメータおよびビューアの絵をファイルに保存します.これらは後からランサマリを作成するときや,Web-KiNOKO などで使用されます.KCOM フレームワーク内のレジストリサーバは,レジストリの内容を定期的にファイルに書きだします.レジストリには,コンポーネントの動作状態などの情報が記録されているので,このファイルを読むことによりシステムの動作状況を把握することができます.この機能は Web-KiNOKO のシステムモニタで使用されており,将来 SmallKinoko にもこの機能を利用したシステムモニタが導入される予定です.コントロールパネルでは,ウィジェットの値をファイルに書き出したりファイルから読み込んだりすることができ,これは起動時のデフォルト値のロードや Web-KiNOKO で使われています.
SmallKinoko.kcom において,コンポーネント宣言は以下のようになっています.
import KinokoCollector;
import KinokoBuffer;
import KinokoRecorder;
import KinokoViewer;
import KinokoController;
import KinokoLogger;
import KinokoReporter;
import KinokoTransporter;
component KinokoController controller(host, ui_control);
component KinokoReporter reporter(host);
component KinokoCollector collector(daq_host);
component KinokoBuffer buffer(host);
component KinokoRecorder recorder(host);
component KinokoViewer viewer(host, ui_view);
component KinokoLogger logger(host, ui_log);
component KinokoTransporter analyzer(host);
ここで,host や ui_control, ui_view, ui_log などは環境変数や起動時引数などから決定される文字列です.デフォルトでは host と daq_host は同じ中身ですが,ここを変えることにより,Collector コンポーネントを他の PC に配置することができます.
Controller,Viewer および Logger に接続される KinokoShell のプロセスも,KCOM スクリプトの先頭付近で起動されます.
execute("kinoko-control --client " + host + " " + port_control);
execute("kinoko-board --client " + host + " " + port_log);
execute("kinoko-canvas --client " + host + " " + port_view);
on startup() では,ロガー,レポーターおよびコントロールパネルのスタート,データストリームの接続(connect() 関数の呼び出し)を行います.この際にエラーが検出されなければ,コントローラのステートを stream_ready に設定することにより,コントロールパネル上の Construct および Quit ボタンを操作できるようにします.
on startup()
{
setTimeout(kcom_timeout_sec);
logger.startLogging(log_dir + "/" + log_file_name);
reporter.open(log_dir + "/" + report_file_name);
controller.open(kcml_script);
if (web_dir != "") {
controller.loadScript(web_dir + "/kweb-export-kcv.kcms");
controller.execute("setWebDirectory", web_dir);
}
if (kcms_script != "") {
println("loading " + kcms_script + "...");
controller.loadScript(kcms_script);
}
collector.enableConditionMonitor();
analyzer.enableConditionMonitor();
recorder.enableConditionMonitor();
viewer.enableConditionMonitor();
buffer.enableConditionMonitor();
controller.changeState("component_ready");
connect();
if (error_count == 0) {
controller.changeState("stream_ready");
}
else {
controller.setWidgetValue("message", "error: click [quit] to shutdown");
controller.changeState("error");
}
}
Web-KiNOKO 用に,ビューアの絵とレジストリ値を5秒ごとに保存するように on every が使われています.
on every (5 sec) {
saveRegistry(log_dir + "/" + registry_file_name);
if ((web_dir != "") && (is_running)) {
viewer.saveImage(web_dir + "/" + figure_file_name);
}
}
データストリーム接続を確立する connect() 関数の中身は以下のようになっています.受動的に動作する Buffer をまずスタートし,次に全てのコンポーネントに接続相手を指定してから connect() イベントを送り出します.効率を良くするために,非同期で実行できるブロックが asynchronous 指定されています.
void connect()
{
buffer.start();
asynchronous {
collector.setSink(analyzer);
analyzer.setSourceSink(collector, buffer);
recorder.setSource(buffer);
viewer.setSource(buffer);
}
asynchronous {
collector.connect();
analyzer.connect();
recorder.connect();
viewer.connect();
}
}
ここまでで,コンポーネントが配置され,データストリームが接続されて,ユーザのコマンド待ちの状態になりました.ユーザは コントロールパネル上にパラメータ(読みだしスクリプトやデータファイル名など)を設定し Construct をクリックするか,Quit をクリックすることができます.KCML スクリプトにより,Construct ボタンがクリックされると KCOM に construct イベントが通知され,Quit ボタンがクリックされると quit イベントが通知されるようになっています(Button ウィジェットの name 属性が指定されているだけ).
KCOM が construct イベントを受け取ると,KCOM スクリプトの on .construct() が呼び出されます.ここでは,construct() 関数を呼び出してエラーチェックの後ステートを system_ready に設定します.すでに construct されている場合には,construct() 関数を呼び出す前に destruct() 関数を呼び出します.
on .construct()
{
if (is_constructed) {
destruct();
is_constructed = false;
}
controller.changeState("constructing");
controller.setWidgetValue("message", "constructing...");
if (construct() && (error_count == 0)) {
controller.changeState("system_ready");
controller.setWidgetValue("message", "ready to start data acquisition");
is_constructed = true;
}
else {
controller.changeState("stream_ready");
controller.setWidgetValue("message", "construction failed: try again.");
}
}
以下は,construct() 関数の中身です.コントロールパネル上のパラメータをレジストリ経由で取得して,レポーターに記録し,コンポーネントに設定して,最後に各コンポーネントをコンストラクトしています.
int construct()
{
string run_name = getRegistry("control/run_name");
string comment = getRegistry("control/comment");
readout_script = getRegistry("control/readout_script");
view_script = getRegistry("control/view_script");
data_file = getRegistry("control/data_file");
oneway {
reporter.write("run-name", run_name);
reporter.write("comment", comment);
reporter.write("date", localTime());
(中略)
}
oneway {
collector.setReadoutScript(readout_script);
viewer.setViewScript(view_script);
recorder.setDataFile(data_file);
(中略)
}
asynchronous {
collector.construct();
analyzer.construct();
recorder.construct();
viewer.construct();
}
return 1;
}
これで,データ収集を開始する準備が整いました.ユーザはコントロールパネルの start をクリックすることができ,これにより KCOM の on .start() が呼ばれ,KCOM Script ではこの中で Collector の start() を呼び出します.
停止とシャットダウンは,基本的には上記手順の逆順ですが,停止には注意する必要があります.フロントエンドの Collector に Stop を送っても,データストリームにデータが残っている場合は,これらが全て処理されるのを待たなければならないからです.
Recorder はストリームから送られてくる RunBegin パケットと RunEnd パケットを数えており,RunBegin と同じ数の RunEnd を受け取ると finishRecording() イベントを発行します.SmallKinoko ではこれを利用して,全てのデータ処理が終了するまで Destruct できないようにしています.
on .stop()
{
controller.changeState("stopping");
controller.setWidgetValue("message", "stopping...");
stop();
}
void stop()
{
collector.stop();
}
on recorder.finishRecording()
{
controller.changeState("system_ready");
controller.setWidgetValue("message", "ready to start data acquisition");
saveRegistry(log_dir + "/" + registry_file_name);
}
データ収集の停止は,コントロールパネルからのユーザの操作だけではなく,指定時間の経過や,ディスクスペースの不足などによっても引き起こされます.SmallKinoko では,これらのイベント受け取った際も stop() を呼ぶようになっています.
on collector.dataAcquisitionFinished()
{
controller.changeState("stopping");
controller.setWidgetValue("message", "stopping...");
stop();
}
on recorder.diskSpaceExhausted()
{
logger.writeError("disk space exhausted");
if (is_running) {
controller.changeState("stopping");
controller.setWidgetValue("message", "stopping...");
stop();
}
}
コントロールパネルの quit が押されたら,スタートアップ時と逆順で終了処理をし,最後に exit して KCOM 自体も終了します.
on .quit()
{
controller.changeState("shutdown");
controller.setWidgetValue("message", "shutting down...");
if (is_constructed) {
is_constructed = false;
destruct();
}
disconnect();
quit();
sleep(1);
exit;
}
destruct() 関数,disconnect() 関数および quit() 関数の中身については $KINOKO_ROOT/scripts/SmallKinoko.kcom を参照してください.基本的に起動手順の逆ですが,Buffer については,特に能動的な動作をしないため,最後に quit() しているだけです.
SmallKinoko の拡張例1:Collector コンポーネントを2つ使う
SmallKinoko 拡張の例として,Collector コンポーネントを2つ使うように SmallKinoko.kcom を書き換えてみます.ここで作成する KCOM および KCML スクリプトは kinoko/local/tutorials/KcomScript にあります.SmallKinoko.kcom との diff をとることにより,必要な変更が一覧できます.
% diff -c SmallKinoko.kcom DualCollector.kcom
この例では,2つの Collector コンポーネントを別々のフロントエンドPCに配置することにします.2つの Collector からのストリームの合流には Buffer を使用します.現在のところ,Buffer は共有メモリを直接使用しているため,ネットワーク越しでの直接の接続はできないことに注意してください.このため,それぞれの Collector にひとつづつ Transporter コンポーネントが接続されています(名前は analyzer).
SmallKinoko とのいちばん大きな違いは,Collector と Transporter を2つづつ使う点です.これらの component 宣言は以下のようになります.
component KinokoController controller(host, ui_control);
component KinokoReporter reporter(host);
component KinokoCollector collector1(daq_host_1);
component KinokoCollector collector2(daq_host_2);
component KinokoBuffer buffer(host);
component KinokoRecorder recorder(host);
component KinokoViewer viewer(host, ui_view);
component KinokoLogger logger(host, ui_log);
component KinokoTransporter analyzer1(host);
component KinokoTransporter analyzer2(host);
ここで,daq_host_1 および daq_host_2 にはフロントエンドPCのホスト名を適切に設定しておきます.
注意
この例では複数のPCを連系させて使用します.この例を実行するには Kinoko がネットワーク越しに動作するように,以下の設定がされていなければなりません.
- 使用する全ての PC の同じディレクトリに Kinoko がインストールされていること
- 使用する全ての PC に同じログイン名でパスワードなしで ssh できるように設定されていること
- 使用する全ての PC が相互に参照できるようにネットワークが設定されていること.
- 使用する全ての PC においてネットワーク上の自分の名前が取得できるように設定されていること ("hostname -i" コマンドおよび kinoko/src/kernel/lib-common/mush/samples にある network-test を実行して表示されるホスト名やアドレスが localhost や 127.0.0.1 ではないこと).
connect() 関数の中身は,ストリーム接続構成を反映して,以下のようになります.
void connect()
{
buffer.start();
asynchronous {
collector1.setSink(analyzer1);
collector2.setSink(analyzer2);
analyzer1.setSourceSink(collector1, buffer);
analyzer2.setSourceSink(collector2, buffer);
recorder.setSource(buffer);
viewer.setSource(buffer);
}
asynchronous {
collector1.connect();
collector2.connect();
analyzer1.connect();
analyzer2.connect();
recorder.connect();
viewer.connect();
}
}
ふたつの Collector で別々の読みだしスクリプトを使うこともできますが,ここではひとつのスクリプトの異なったデータソースを使うことにします.ひとつの kts スクリプトの中には複数の datasource エントリを作成でき,大域変数や関数などを共有することができるので,ひとつのシステムとして動作するものの読みだしスクリプトはこの例のようにひとつにまとめておくと便利で,また,管理も楽になります.
construct() 関数のデータソースを指定する部分は以下のようになります.
int construct()
{
readout_script = getRegistry("control/readout_script");
view_script = getRegistry("control/view_script");
data_file = getRegistry("control/data_file");
string datasource1 = getRegistry("control/datasource1");
string datasource2 = getRegistry("control/datasource2");
// 中略
oneway {
collector1.setReadoutScript(readout_script, datasource1);
collector2.setReadoutScript(readout_script, datasource2);
viewer.setViewScript(view_script);
recorder.setDataFile(data_file);
// 中略
}
asynchronous {
collector1.construct();
collector2.construct();
analyzer1.construct();
analyzer2.construct();
recorder.construct();
viewer.construct();
}
return 1;
}
これに合わせて,コントロールパネルの方もデータソースを指定できるように変更します.ここでは,複雑さを避けるために SmallKinoko-Lite.kcml をベースにしていますが,SmallKinoko.kcml をベースにしても基本的に同様です.
多くの場合,複数のPCを使用するような大きなシステムでは読み出しスクリプトは固定するか,少なくともデータソース名は決まっている(crate01 など)ので,ここで行うようにコントロールパネルから変更できるようにする必要はあまり多くないと思います.スクリプト名やデータソース名を固定していい場合には,KCML の Constant ウィジェットを使うか KCOM に直書きするのが簡単です.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="kweb-control-panel.xsl"?>
<KinokoControlPanel label="Kinoko Control Panel">
<HSpace/><Label name="message" label="Welcome to KiNOKO." font="times-italic"/><HSpace/>
<VSpace/>
<EntryList>
<Entry name="readout_script" label="ReadoutScript (.kts)" option="file_select"/>
<Entry name="view_script" label="ViewScript (.kvs)" option="file_select"/>
<Entry name="data_file" label="DataFile (.kdf)" option="file_select"/>
</EntryList>
<VSpace/>
<Frame label="Datasource Names">
<EntryList>
<Entry name="datasource1" label="Collector 1"/>
<Entry name="datasource2" label="Collector 2"/>
</EntryList>
</Frame>
<NewLine/>
<Frame name="run_control" label="Run Control">
<ButtonList>
<Button name="construct" label="Construct" enabled_on="stream_ready system_ready"/>
<Button name="start" label="Start" enabled_on="system_ready"/>
<Button name="stop" label="Stop" enabled_on="data_taking"/>
<Button name="clear_images" label="Clear" enabled_on="system_ready data_taking"/>
<Button name="quit" label="Quit" enabled_on="stream_ready system_ready error"/>
</ButtonList>
</Frame>
</KinokoControlPanel>
start() では,両方の Collector をスタートします.stop() も同様です.これにより,Buffer より下流では RunBegin と RunEnd がそれぞれふたつづつ送られるようになります.Recorder の finishRecording() は,このような状況でも適切に動作します.
void start()
{
collector1.start();
collector2.start();
// 中略
}
void stop()
{
collector1.stop();
collector2.stop();
// 中略
}
作成した KCOM スクリプトは kinoko コマンドで起動します.
% kinoko DualCollector.kcom
SmallKinoko の拡張例2:Viewer コンポーネントを2つ使う
次に,Viewer コンポーネントを2つ使用して多くのプロットを表示できるようにする例を見てみます.ここで作成する KCOM および KCML スクリプトは kinoko/local/tutorials/KcomScript にあります.
Viewer を2つ使用する場合でも,Collector の例と同様に,Buffer をストリームの分岐に使用することができます.しかし,ここでは,ChainedStreamSink の機能を使って Viewer コンポーネントをチェーン上に一列に接続する構成をとることにします.
システム構成にもよりますが,Buffer はシステムのボトルネックになりやすいため,多数の StreamSink コンポーネント(Viewer や Recorder)を使用する場合はこのような構成にするほうが性能が向上することが多いようです.また,全体的な性能が不足した場合,StreamSinkChain の一部を別PCに移動することも容易にできるという利点もあります(component 宣言部分の引数を変えるだけ).
Viewer が2つあるため,kinoko-canvas も2つ用意します.接続用のポートも別々に割り当てる必要があります.KCOM スクリプトの先頭付近は以下のようになります.
int port_control = port_base;
int port_log = port_base + 1;
int port_view1 = port_base + 2;
int port_view2 = port_base + 3;
string ui_control = "port: " + port_control;
string ui_log = "port: " + port_log;
string ui_view1 = "port: " + port_view1;
string ui_view2 = "port: " + port_view2;
execute("kinoko-control --client " + host + " " + port_control);
execute("kinoko-board --client " + host + " " + port_log);
execute("kinoko-canvas --client " + host + " " + port_view1);
execute("kinoko-canvas --client " + host + " " + port_view2);
component KinokoController controller(host, ui_control);
component KinokoReporter reporter(host);
component KinokoCollector collector(daq_host);
component KinokoBuffer buffer(host);
component KinokoRecorder recorder(host);
component KinokoViewer viewer1(host, ui_view1);
component KinokoViewer viewer2(host, ui_view2);
component KinokoLogger logger(host, ui_log);
component KinokoTransporter analyzer(host);
connect() 関数は以下のようになります.この例のようにストリームシンクの Viewer をチェーン接続する場合は,ストリームパイプの場合と同様に setSourceSink() を使って接続先を指定します.
void connect()
{
buffer.start();
asynchronous {
collector.setSink(analyzer);
analyzer.setSourceSink(collector, buffer);
recorder.setSource(buffer);
viewer1.setSourceSink(buffer, viewer2);
viewer2.setSource(viewer1);
}
asynchronous {
collector.connect();
analyzer.connect();
recorder.connect();
viewer1.connect();
viewer2.connect();
}
}
ビューアが2つあるので,ここでは2つのビュースクリプトを使うことにします(前章の例と同様に,ひとつのスクリプトの異なる display エントリを指定することもできます).construct() 関数の中身は以下のようになります.
int construct()
{
string readout_script = getRegistry("control/readout_script");
string view_script_1 = getRegistry("control/view_script_1");
string view_script_2 = getRegistry("control/view_script_2");
string data_file = getRegistry("control/data_file");
// 中略
oneway {
collector.setReadoutScript(readout_script);
viewer1.setViewScript(view_script_1);
viewer2.setViewScript(view_script_2);
recorder.setDataFile(data_file);
// 中略
}
asynchronous {
collector.construct();
analyzer.construct();
recorder.construct();
viewer1.construct();
viewer2.construct();
}
return 1;
}
これに合わせて,コントロールパネルも2つのビュースクリプトを指定できるように変更します.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="kweb-control-panel.xsl"?>
<KinokoControlPanel label="Kinoko Control Panel">
<HSpace/><Label name="message" label="Welcome to KiNOKO." font="times-italic"/><HSpace/>
<VSpace/>
<EntryList>
<Entry name="readout_script" label="ReadoutScript (.kts)" option="file_select"/>
<Entry name="view_script_1" label="ViewScript 1 (.kvs)" option="file_select"/>
<Entry name="view_script_2" label="ViewScript 2 (.kvs)" option="file_select"/>
<Entry name="data_file" label="DataFile (.kdf)" option="file_select"/>
</EntryList>
<VSpace/>
<Frame name="run_control" label="Run Control">
<ButtonList>
<Button name="construct" label="Construct" enabled_on="stream_ready system_ready"/>
<Button name="start" label="Start" enabled_on="system_ready"/>
<Button name="stop" label="Stop" enabled_on="data_taking"/>
<Button name="clear_images" label="Clear" enabled_on="system_ready data_taking"/>
<Button name="quit" label="Quit" enabled_on="stream_ready system_ready error"/>
</ButtonList>
</Frame>
</KinokoControlPanel>
以上で終了です.これで,描画ウィンドウが2つあるシステムが使用できるようになりました.
% kinoko DualViewer.kcom
前章の Collector コンポーネントを増やして複数の計算機に分散させる例と組み合わせたり,analyzer を独自のデータ解析コンポーネントと置き換えたりすることにより,現段階でもかなり複雑なシステムを組み上げることができるようになっています.
モジュールドライバの作成
Kinoko でハードウェアを操作しデータを読むためには,そのモジュールの動作を Kinoko に教えるためのコード,すなわちモジュールドライバ (KinokoModuleDriver) が必要です.Kinoko のパッケージにはすでにいくつかのモジュールドライバのコードが付属しており,使用できるモジュールの一覧は kinoko-lsmod コマンドで一覧できます.CAMAC モジュールに関しては,Generic-CamacModule でそのまま使用できるものも多くあります.詳細については,リファレンス > モジュールドライバリファレンス の章を参照してください.
現在サポートされていないデバイスを使用する場合は,モジュールドライバを独自に作成して Kinoko に組み込む必要があります.Kinoko は VME および CAMAC を使用するためのモジュールドライバフレームワークを提供しており,これを用いればハードウェアの詳細部分をかなり簡略化できます.一方で,製品付属のライブラリや外部ソフトウェアパッケージを使用することも可能で,これにより GPIB や データ収集 PCI カードなどのデバイスからデータを読み出すことも,イベントジェネレータのようなシミュレーションパッケージから疑似データを取得することもできるようになります.
簡単な例
ここでは,Linux カーネルの乱数生成機構である /dev/random を仮想的なデバイスと見て,ここから読み出しを行って乱数を生成するモジュールドライバを作り,それを Kinoko に追加してみます.この例の完全なコードは kinoko/local/tutorials/ModuleDriver/SoftwareModule にあります.
/dev/random は,いろいろなデバイスドライバなどの動作(環境ノイズ)をもとに疑似ではない乱数を生成するカーネルインターフェースで,/dev/random 自体は普通のキャラクタ型デバイスのようにアクセスできます.read() をすれば乱数をかえしてきます.もし,乱数の生成に十分な「エントロピー」がなければ,必要な環境ノイズが得られるまで read() はブロックされます.この振舞いは,データ収集デバイスの読み出しとデータ待ちに似ています./dev/random の詳細については,Linux のマニュアルページ random(4) を参照してください.
この例では,以下のファイルを作成します.
- module-DevRandom.cc: モジュールドライバ本体
- module-DevRandom.hh: モジュールドライバヘッダ
- DevRandom-test.cc: モジュールドライバを単体テストするプログラム
- DevRandom.kts: 作成したモジュールドライバをテストするための読み出しスクリプト
- Makefile: メイクファイル
モジュールドライバは全て,間接的に TRoomModule の派生クラスとなります.VME および CAMAC のモジュールドライバはそれぞれ TRoomVmeModule および TRoomCamacModule から派生させ,その他のデバイスは現時点では TRoomSoftwareModule から派生させます.これらは全て TRoomModule の派生クラスです.これらのクラスの詳細については,拡張方法 の モジュールドライバを書く の章を参照してください.
モジュールドライバのインターフェースの中で,最低限実装しなければならないのが,コンストラクタ,デストラクタと Clone() メソッドです.Clone() では,自分自身と同じ型のインスタンスをひとつ生成して,そのポインタを返すようにします.
TSoftwareModule_DevRandom::TSoftwareModule_DevRandom(void)
: TRoomSoftwareModule("DevRandom", "Software_DevRandom")
{
_DeviceFile = -1;
}
TSoftwareModule_DevRandom::~TSoftwareModule_DevRandom()
{
}
TRoomSoftwareModule* TSoftwareModule_DevRandom::Clone(void)
{
return new TSoftwareModule_DevRandom();
}
これに加えて,以下のメソッドをオーバーライドしておくと,Kinoko がいろいろな場面でデータサイズ等を自動管理し,最適化します.
int TSoftwareModule_DevRandom::NumberOfChannels(void) throw(THardwareException)
{
return 16;
}
int TSoftwareModule_DevRandom::AddressBitLength(void)
{
return 4;
}
int TSoftwareModule_DevRandom::DataBitLength(void)
{
return 16;
}
Initialize() メソッドと Finalize() メソッドをオーバーライドしておくと,それぞれデータ収集開始直前と終了直後に呼び出されるようになります.ここでは,このタイミングで /dev/random をオープンおよびクローズをするようにします.
int TSoftwareModule_DevRandom::Initialize(int InitialState) throw(THardwareException)
{
_DeviceFile = open("/dev/random", O_RDONLY);
if (_DeviceFile < 0) {
throw THardwareException(
"TSoftwareModule_DevRandom::Initialize()",
"unable to open file: /dev/random"
);
}
return 0;
}
int TSoftwareModule_DevRandom::Finalize(int FinalState) throw(THardwareException)
{
if (_DeviceFile >= 0) {
close(_DeviceFile);
_DeviceFile = -1;
}
return 0;
}
データの読み出しを行えるようにするためには,Read() メソッドをオーバーライドします.戻り値はデータのサイズで,失敗したら例外 THardwareException を投げます.データが存在しない場合は例外を投げるのではなく,0 を返すようにします.
int TSoftwareModule_DevRandom::Read(int Address, int &Data) throw(THardwareException)
{
U16bit Buffer;
int Result = read(_DeviceFile, &Buffer, sizeof(Buffer));
if (Result < 0) {
if (errno == EINTR) {
return this->Read(Address, Data);
}
else {
throw THardwareException(
"TSoftwareModule_DevRandom::Read()", strerror(errno)
);
}
}
Data = Buffer;
return Result;
}
ここまでで,読み出しスクリプトから read(), taggedRead() および sequentialRead() が使えるようになっています(sequentialRead() は上記 Read() メソッドが 0 を返すまで繰り返し Read() を呼び出すので,この例では修正が必要です).
読み出しスクリプトで,このモジュールをシーケンス開始条件に使う(on trigger に使う)ためには,HasData() メソッドをオーバライドしてデータが読み出し可能かどうかを Kinoko に伝えるようにします.データが存在すれば true を,そうでなければ false を返すようにします.同時に,この例では必要ありませんが,モジュール上のデータをクリアするメソッド Clear() もオーバライドしておきます.一般には,Clear() で HasData() の条件もクリアし,次のデータの到着を待つようにします.
bool TSoftwareModule_DevRandom::HasData(int Address) throw(THardwareException)
{
struct pollfd fds;
fds.fd = _DeviceFile;
fds.events = POLLIN;
if (poll(&fds, 1, 0) < 0) {
throw THardwareException(
"TSoftwareModule_DevRandom::HasData()", strerror(errno)
);
}
return fds.revents & POLLIN;
}
int TSoftwareModule_DevRandom::Clear(int Address) throw(THardwareException)
{
return 0;
}
ここまでで,読み出しスクリプトでこのモジュールを on trigger の条件に使うことと,waitData() を使うことができるようになりました.この時点でのこのモジュールドライバのクラス定義は以下のようになっています.
class TSoftwareModule_DevRandom: public TRoomSoftwareModule {
public:
TSoftwareModule_DevRandom(void);
virtual ~TSoftwareModule_DevRandom();
virtual TRoomSoftwareModule* Clone(void);
virtual int NumberOfChannels(void) throw(THardwareException);
virtual int AddressBitLength(void);
virtual int DataBitLength(void);
virtual int Initialize(int InitialState = 0) throw(THardwareException);
virtual int Finalize(int FinalState = 0) throw(THardwareException);
virtual bool HasData(int Address = -1) throw(THardwareException);
virtual int Clear(int Address = -1) throw(THardwareException);
virtual int Read(int Address, int &Data) throw(THardwareException);
protected:
int _DeviceFile;
};
最後に,このモジュールドライバを Kinoko に自動登録するためのトリッキーなコードを module-DevRandom.cc の先頭付近に追加します.
static TRoomSoftwareModuleCreator Creator(
"DevRandom", new TSoftwareModule_DevRandom()
);
make をすると,モジュールドライバ module-DevRandom.o と,それを単体テストする DevRandom-test が生成されます.モジュールドライバの開発過程で毎回 Kinoko を再構築し,Kinoko を起動しているとかなり面倒なので,このような単体テストコードを使用すると便利です.このソース DevRandom-test.cc は,先頭付近のデバイス名を変えるだけで他のモジュールドライバへの転用が容易なように書かれています.
% make
% ./DevRandom-test
単体テストで問題がなければ,これを Kinoko に組込みます(データレートが低い場合はマウスをぐりぐり動かしてください).このソースコードを Kinoko のソースツリーに組み込んで全体を再コンパイルしても良いのですが,ここではモジュールドライバのみを kinoko/devices にコピーして,必要な部分だけ再コンパイルをするようにします.Makefile にはすでにこれを行うコードが書かれていますので,これを使います.
% make rebuild-kinoko
これで,Kinoko からこのモジュールドライバが使えるようになっているはずです.tinykinoko からテストスクリプトを実行して確認します.
% tinykinoko DevRandom.kts test.kdf 100
% kdfdump test.kdf
/dev/random は,乱数を生成するのに十分なハードウェアイベントが起こらないとデータを返しません.この例では,トリガがかからないことになります.なかなか先に進まない場合は,マウスを動かすなどしてハードウェアイベントをたくさん起こすようにしてください.
その他のインターフェース
上記の例は,Read() のみを行う非常に単純なものでした.モジュールドライバには,より複雑な状況で使われる様々なインターフェースがあります.以下にその例をいくつか示します.詳細については,拡張方法 の モジュールドライバを書く の章を参照してください.
- SequentialRead() と NextNumberOfDataElements() を実装すると,sequentialRead() の効率がかなり向上します.また,モジュールによっては,この方法でのみ読み出しができるような構造のものもあります.
- BlockRead() と NextDataBlockSize() を実装すると,ブロック読み出し (読み出しスクリプトの blockRead() アクション) が使用できるようになります.また,モジュールによっては,この方法でのみ読み出しができるような構造のものもあります.
- HasData() に加えて,WaitData() を実装しておくと,Kinoko が単純な構成での不要なポーリングループを避けられるようになり,効率が向上します.また,モジュールが割り込みなどを使用できる場合は,サービスリクエスタのインターフェースを実装しておくと,トリガの多面待ちなどの状況での性能がかなり向上します.
- モジュールとのデータのやりとりは,Read() 系に加えて,ReadRegister() および WriteRegister() が使用できます.これらが実装されていると,読み出しスクリプトからも同名のメソッドを介してモジュールの設定などができるようになります.
- 複雑な機能を持ったモジュールでは,MiscControl() インターフェースを実装することにより,一連のレジスタアクセスなどをまとめてひとつのアクションとすることができます.例えば,Kinoko に付属の LeCroy ADC/TDC Tester では,この機能により多数の設定アクションが利用できるようになっています.
VME および CAMAC
上記の例のような SoftwareModule では,ハードウェアインターフェースに関しては Kinoko からのサポートは一切ありませんでした.これに対し,VME や CAMAC を使う場合,TRoomVmeModule や TRoomCamacModule からモジュールドライバを派生させることにより,これらのクラスで定義されている多くのユーティリティメソッドを利用できるようになります.例えば,VME なら,メモリマッピングや DMA 転送などが,CAMACなら CAMAC サイクルの実行や LAM の操作などが,コントローラの種類によらず同じインターフェースで利用できます.これらの詳細については,拡張方法 の モジュールドライバを書く の章を参照してください.
データファイルの読み方 0 - ダンプツールを使う -
TinyKinoko や SmallKinoko などでとったデータは,KDF (Kinoko Data Format) 形式のファイルで保存されます.これはデータの他にヘッダやデータデスクリプタなどのさまざまな情報を含んだバイナリファイルで,kdfdump や kdftable などの標準ユーティリティでテキストに変換できます.また,kdfprofile や kdfcheck などを使うと,そのデータを取るときに使ったスクリプト名やその他のさまざまな設定を見ることができます.
kdfdump
kdfdump コマンドを使うと,KDF ファイルに書かれている全てのデータを表示させることができます.以下は,kdfdump コマンド出力の例です.
% kdfdump test01.kdf -
# Creator: tinykinoko
# DateTime: 2008-05-28 13:18:54 JST
# UserName: sanshiro
# Host: kinoko.awa.tohoku.ac.jp
# Directory: /home/sanshiro/work/kinoko/local/test01
# ScriptFile: Test01.kts
# EventTime: 1211948334
# EventTime: 1211948334
adc 0 1970
adc 1 1043
adc 2 1505
adc 3 339
# EventTime: 1211948334
adc 0 1216
adc 1 1411
adc 2 972
adc 3 183
adc 0 1521
adc 1 1510
adc 2 885
adc 3 1369
# EventTime: 1211948335
adc 0 173
adc 1 2022
adc 2 1016
adc 3 704
(以下省略)
kdfdump のコマンド書式は以下のようになっています.
kdfdump [オプション] データファイル名 [データソース名 [データセクション名 ...]]
第2引数のデータソース名に - を指定するとファイルの中の最初のデータソースが指定されたことになります.データソース名を省略すると全てのデータソースを表示します.第3引数のセクション名は表示対象を限定するもので,省略した場合は全てのセクションを表示します.セクション名は複数指定することができます.
kdfdump の出力は,以下のようになっています.
- 最初にストレージヘッダの内容が 行頭に # を付けて表示される
- イベント区切り (EventTrailer) の位置に空行が挿入される
- データソースが指定されていない場合は,パケットの先頭位置に ###[データソース名]### と書かれた行が挿入される
- 一行にひとつのデータエレメントが,セクション名,アドレス,データの順で空白区切りで表示される.
- 時間情報のあるパケットについては,# EventTime: タイムスタンプ が表示される.ここで,タイムスタンプは UNIX の time(2) の形式.
バイナリデータブロックのダンプ
block 型のデータについては,16進のダンプが表示されます.バイナリデータのまま出力したい場合は,--binary オプションを指定します.
% kdfdump --binary test01.kdf - > test01.out
ただし,ここで書き出されるのはデータ本体のみ(モジュールから読み出されたデータブロックそのもの)で,ストレージヘッダやセクション名などは含まれません.もしデータブロック本体だけではチャンネルやデータサイズなどが分からなくなってしまう場合は,--packet オプションを指定して,パケット全体をダンプします.
% kdfdump --packet test01.kdf - > test01.out
パケットは,データブロックの先頭に32ビットワードが3ワード付加された形をしており,この中にデータソースIDやセクションIDが書かれています.
データパケットは 32bit にアラインされていることに注意してください.つまり,DataArea のサイズが 4 バイトの整数倍でない場合,末尾に1バイトから3バイトが挿入されることになります.パケットのサイズは,データを格納できる最小の4の倍数バイトとなります.
データソースIDやセクションIDからデータソース名やセクション名を特定するには,kdfcheck ユーティリティを使い,その先頭部分を見ます.
% kdfcheck test01.kdf | more
% Preamble Version: 00010002
% Header Version: 00010001
% Data Area Version: 00010002
% Data Format Flags: 00000000
# Creator: tinykinoko
# DateTime: 2008-06-13 17:31:23 JST
# UserName: sanshiro
# Host: kinoko
# Directory: /home/sanshiro/kinoko/local/samples
# ScriptFile: CamacAdc.kts
[29373]--- 0, 388 bytes @1f0
Data Descriptor
datasource "CamacAdc"<29373>
{
attribute creator = "tinykinoko";
attribute creation_date = "2008-06-13 17:31:23 JST";
attribute host_name = "kinoko";
attribute user_name = "sanshiro";
attribute script_file = "CamacAdc.kts";
attribute script_file_fingerprint = "6355550a";
section "adc"<257>: indexed(address: int-5bit, data: int-16bit);
}
[29373]--- 1, 12 bytes @378
Command: 1 RUN_BEGIN, 1213345883 (13 Jun 2008 17:31:23 JST)
[29373]--- 2, 12 bytes @388
Command: 5 CLOCK_TICK, 1213345883 (13 Jun 2008 17:31:23 JST)
(以下省略)
これにより,データソース CamacAdc のデータソースIDは 29373,セクション adc のセクションIDは 257 であることが分かります.kdfdump でバイナリダンプして解析するのは一時的な用途を想定していますが,もし継続的行うのならば,読み出しスクリプトでデータソースIDやセクションIDを固定するようにしておくと便利です.
kdftable
kdfdump は KDF ファイル内のデータを全て表示することを目的としており,その出力内容はデータの中身によりいろいろと変化してしまいます(データ数やセクションの有無など).もしデータの構造が単純なものなら,kdftable を使うとより扱いやすい形式の出力が得られます.
% kdftable test01.kdf
# Creator: tinykinoko
# DateTime: 2008-05-28 13:18:54 JST
# UserName: sanshiro
# Host: kinoko.awa.tohoku.ac.jp
# Directory: /home/sanshiro/work/kinoko/local/test01
# ScriptFile: Test01.kts
# Fields: index time adc.0 adc.1 adc.2 adc.3
# StartTime: 1211948334
0 0 1970 1043 1505 339
1 0 1216 1411 972 183
2 1 1521 1510 885 1369
3 1 173 2022 1016 704
4 2 1632 1518 1075 1951
(以下省略)
kdftable のコマンド書式は以下のようになっています.
kdftable [オプション] データファイル名 [データソース名 [データセクション名 ...]]
第2引数のデータソース名に - を指定するか,指定を省略するとファイルの中の最初のデータソースが指定されたことになります.第3引数のセクション名は表示対象を限定するもので,省略した場合は全てのセクションを表示します.セクション名は複数指定することができます.
kdftable の出力は,以下のようになっています.
- 最初にストレージヘッダの内容が 行頭に # を付けて表示される
- 表示対象のデータの名前が # Fields: の後ろに表示される
- スタートした時間が UNIX の time(2) 形式で # StartTime: の後ろに表示される
- indexed 型のデータ(主にモジュールから読み出したデータ)について,イベント番号,スタートからの経過秒数,データが1イベント1行で空白区切りで表示される
- tagged 型のデータ(スクリプトから DataRecord で記録したデータなど)について,「# セクション名.フィールド名 データ」の形式で1エレメント1行で表示される
kdftable は,このように表形式で出力できるデータにのみ対応しています.多くの単純なモジュールで使えますが,フラッシュADCやマルチヒットTDCなどには使えません.
Kinoko では,データが存在しないチャンネルからデータ読み出しを行った場合,そもそもデータの記録を行いません.特に,CAMAC などで複数のモジュールからの読み出しを行っていて,一部のモジュールが Q レスポンスを返さなかったら,そのモジュールからのデータはそのイベントに含まれないことになります.kdftable では,そのようなデータが存在しないチャンネルがあった場合,データフィールドに - を表示します.
もし一部データの欠落が最初のイベントに起こると,その時点では欠落を検出できないため,- を表示することができません.そのため,次以降のイベントのデータフィールドがずれ,結果的に正しいデータの側が - と表示されることになってしまいます(正確には,表示データと先頭のフィールド情報が一致しないときに - が表示されます).この問題を避けるために,データの欠落が予想される場合には,読み出しスクリプトの章で説明している setInvalidDataValue 関数を使って「データがないことを示す値」を設定してください.
自作の解析プログラムなどから kdftable の出力を読むためには,行ごとに読み込み,空行と # から始まる行を飛ばして,空白区切りで数値を読むことになります.
string InputFileName = "test01.knt";
ifstream InputFile(InputFileName.c_str());
if (! InputFile) {
cerr << "ERROR: unable to open file: " << InputFileName << endl;
exit(EXIT_FAILURE);
}
string Line;
int EventIndex, Time, FieldIndex, Data;
while (getline(InputFile, Line)) {
if (Line.empty() || (Line[0] == '#')) {
continue;
}
istringstream Stream(Line);
Stream >> EventIndex >> Time;
for (FieldIndex = 0; Stream >> Data; FieldIndex++) {
}
}
popen(3) 関数を使ってプログラムから kdftable を呼び出すようにすれば,毎回手動で kdftable を実行したりその結果をファイルに保存したりする必要がなくなり便利です.以下に例を示します(C と C++ が混ざって見苦しいことになっていますが...).
#include <iostream>
#include <sstream>
#include <string>
#include <cstdio>
#include <cstdlib>
using namespace std;
string InputFileName = "test01.kdf";
static const int MaxLineLength = 1024;
int main(void)
{
string Command = "kdftable " + InputFileName;
FILE* InputFile = popen(Command.c_str(), "r");
if (InputFile == NULL) {
cerr << "ERROR: unable to execute command: " << Command;
exit(EXIT_FAILURE);
}
char Line[MaxLineLength];
int EventIndex, Time, FieldIndex, Data;
while (fgets(Line, sizeof(Line), InputFile) != NULL) {
if ((Line[0] == '\n') || (Line[0] == '#')) {
continue;
}
istringstream Stream(Line);
Stream >> EventIndex >> Time;
for (FieldIndex = 0; Stream >> Data; FieldIndex++) {
}
}
pclose(InputFile);
return 0;
}
knt2root
ユーティリティ knt2root を使うと,kdftable の出力を ROOT ファイルに変換できます.kdftable の出力を使うので,kdftable が適用できるデータファイルにしか使えないことに注意してください.
% kdftable test01.kdf > test01.knt
% knt2root test01.knt
ここで,knt2root の第1パラメータは入力ファイル名,第2パラメータは出力ファイル名で,出力ファイル名を省略すると,入力ファイル名の拡張子を .root にしたものが生成されます.入力ファイル名に - を指定すると標準入力から読み込むようになるので,これによって中間ファイルを作らずに直接 KDF から ROOT ファイルへ変換することができます.
% kdftable test01.kdf | knt2root - test01.root
入力が標準入力の場合に出力ファイル名が省略されていると,noname.root というファイルが生成されます.
knt2root は,ROOT の TTree にデータを格納します.knt2root の第3パラメータに TTree の名前を指定できます.指定がない場合の TTree の名前はデータソース名となります.
% root test01.root
root [1] _file0->ls();
TFile** test01.root
TFile* test01.root
KEY: TTree CamacAdc;1 CamacAdc
KEY: TTree CamacAdc_PropertyList;1 CamacAdc_PropertyList
root [2] TTree* CamacAdc = _file0->Get("CamacAdc");
root [3] CamacAdc->Show(0);
======> EVENT:0
index = 0
time = 0
adc.0 = 1970
adc.1 = 1043
adc.2 = 1505
adc.3 = 339
データファイルの読み方 1 - DataAnalyzer を使う -
ここでは,kdfdump などの変換ユーティリティを使わずに,直接 C++ のプログラムから KDF 形式のファイルを読む方法を説明します.ここで使用する例の完全なソースコードは kinoko/local/tutorials/DataAnalyzer にあります.
KDF ファイルを読む方法はいくつかありますが,ここではこのうち一番手軽な DataAnalyzer フレームワークを用いる方法を説明します.DataAnalyzer フレームワークを使うと,データ構造の詳細に煩わされずに統一的で手軽な方法でデータを読むことができます.CAMAC の ADC などで取ったデータを順に処理する場合などに適しています.
一方で,複数のデータソースを同時に扱ったり,未知のデータ構造に対して汎用の処理を行なったりなどの高度な処理をしようとすると,逆に使いにくい面もあります.このような場合は,後述する DataProcessor フレームワークを使うことになります.作成したプログラムを将来コンポーネント化したい場合も, DataProcessor フレームワークを使ってください.
簡単な例
データファイルの例として,1枚の ADC モジュールを kinoko/local/samples にある CamacAdc.kts を使って読んだものを使います.
このデータファイルの中身は以下のようになっています.
% kdfdump test01.kdf -
# Creator: tinykinoko
# DateTime: 2003-03-09 20:10:17 JST
# UserName: sanshiro
# Host: kinoko.awa.tohoku.ac.jp
# Directory: /home/sanshiro/work/kinoko/local/samples
# ScriptFile: CamacAdc.kts
adc 0 258
adc 1 363
adc 2 2073
adc 3 1114
adc 0 298
adc 1 705
adc 2 138
adc 3 1461
(以下省略)
% kdfcheck test01.kdf
% Preamble Version: 00010002
% Header Version: 00010001
% Data Area Version: 00010001
% Data Format Flags: 00000000
# Creator: tinykinoko
# DateTime: 2003-03-09 20:10:17 JST
# UserName: sanshiro
# Host: kinoko.awa.tohoku.ac.jp
# Directory: /home/sanshiro/work/kinoko/local/samples
# ScriptFile: CamacAdc.kts
[2269]--- 0, 308 bytes
Data Descriptor
datasource "CamacAdc"<2269>
{
attribute creator = "tinykinoko";
attribute creation_date = "2003-03-09 20:10:18 JST";
attribute script_file = "CamacAdc.kts";
attribute script_file_fingerprint = "6355550a";
section "adc"<256>: indexed(address: int-16bit, data: int-16bit);
}
(以下省略)
このデータファイルには,データソース CamacAdc のデータのみが入っていて,その中にはセクション adc のみがあることに注意してください.
はじめにやることは,Kinoko のデータ解析フレームワークである KinokoSectionDataAnalyzer クラスを継承して,自分のアナライザクラスを作り,そこで ProcessData() メソッドをオーバーライドすることです.
#include "KinokoKdfReader.hh"
#include "KinokoSectionDataAnalyzer.hh"
class TMyDataAnalyzer: public TKinokoSectionDataAnalyzer {
public:
TMyDataAnalyzer(void);
virtual ~TMyDataAnalyzer();
virtual int ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException);
protected:
int _EventCount;
};
ここではファイル中のデータを全て表示し,最後にイベント数を表示するようにします.メンバの _EventCount はイベント数を数えるためのものです.オーバーライドするメソッドの他に,コンストラクタとデストラクタも必要です.
次にこれらのメソッドの実装です.
static const char* SectionName = "adc";
TMyDataAnalyzer::TMyDataAnalyzer(void)
: TKinokoSectionDataAnalyzer(SectionName)
{
_EventCount = 0;
}
TMyDataAnalyzer::~TMyDataAnalyzer()
{
cout << endl;
cout << _EventCount << " events were processed." << endl;
}
int TMyDataAnalyzer::ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException)
{
_EventCount++;
int Address, Data;
while (SectionData->GetNext(Address, Data)) {
cout << Address << " " << Data << endl;
}
return 1;
}
親クラスである TKinokoSectionDataAnalyzer のコンストラクタには,読みたいデータのセクション名を渡してください.これにより,そのセクションのデータオブジェクトを引数に ProcessData() が呼ばれるようになります.ProcessData() は,ひとつのデータパケットごと呼び出されます.
ProcessData() の中では,そのセクションデータオブジェクトから GetNext() で順にデータを読み出し,表示させます.GetNext() は,そのデータオブジェクトから読み出すデータがなくなると,false をかえします.
最後に,main() 関数を作成し,Kinoko のファイル読み出しをおこなうクラス TKinokoKdfReader のインスタンスを作成して,RegisterAnalyzer() で自分の Analyzer 登録します.TKinokoKdfReader のコンストラクタの引数にはデータファイル名を,RegisterAnalyzer() では読み出したいデータのデータソース名を指定します.この例のようにデータファイルにデータソースが一つしか含まれていない場合,データソース名には空文字列を指定できます.
static const char* DataSourceName = "";
int main(int argc, char** argv)
{
if (argc < 2) {
cerr << "Usage: " << argv[0] << " DataFileName" << endl;
return EXIT_FAILURE;
}
string DataFileName = argv[1];
TKinokoKdfReader* KdfReader = new TKinokoKdfReader(DataFileName);
TKinokoDataAnalyzer* Analyzer = new TMyDataAnalyzer();
try {
KdfReader->RegisterAnalyzer(DataSourceName, Analyzer);
KdfReader->Start();
}
catch (TKinokoException& e) {
cerr << "ERROR: " << e << endl;
return EXIT_FAILURE;
}
delete Analyzer;
delete KdfReader;
return 0;
}
このプログラムをコンパイルするためには,Kinoko のライブラリをリンクする必要があります.
標準ユーティリティ kinoko-config を使うと,必要なライブラリやインクルードパスの指定を自動化できます.以下に,kinoko-config を使用した Makefile の例を示します.
# Makefile for sample DataAnalyzer
CXX = $(shell kinoko-config --cxx)
FLAGS = $(shell kinoko-config --flags)
LIBS = $(shell kinoko-config --libs)
DataAnalyzer01: DataAnalyzer01.o
$(CXX) -o $@ $@.o $(LIBS)
.cc.o:
$(CXX) $(FLAGS) -c $<
このプログラムを実行すると,以下のようになります.
% ./DataAnalyzer01 test01.kdf
0 258
1 363
2 2073
3 1114
0 298
1 705
2 138
3 1461
(中略)
100 events were processed.
%
複数のセクションを読む
つぎに,もうすこし複雑な例として,複数のセクション(複数のモジュール)のデータの読み出しを行ないます.また,イベントとイベントの間に空行を表示させてみます.
前回と同様に,KinokoSectionDataAnalyzer を継承して,自分のアナライザクラスを作成し,ProcessData() をオーバーライドします.また,イベントデータの最後で空行を表示させるために,ProcessTrailer() もオーバーライドします.
class TMyDataAnalyzer: public TKinokoSectionDataAnalyzer {
public:
TMyDataAnalyzer(void);
virtual ~TMyDataAnalyzer();
virtual int ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException);
virtual int ProcessTrailer(int TrailerValue) throw(TKinokoException);
protected:
int _AdcSectionIndex, _TdcSectionIndex;
};
次に,メソッドの実装です.今回は読み出すデータセクションが複数あるので,前回のように TKinokoDataSectionAnalyzer のコンストラクタでセクション名を指定するのではなく,以下のように AddSection() メソッドを使用します.AddSection() は戻り値にデータ種別を区別するための SectionIndex を返すので,その値をメンバ変数に保存しておきます.
ProcessData() では,AddSection() で取得した SectionIndex を使ってデータオブジェクトのセクションを区別します.
ProcessTrailer() では,トレイラの種別を確認して,イベントトレイラなら,イベント区切りの空行を出力します.
TMyDataAnalyzer::TMyDataAnalyzer(void)
{
_AdcSectionIndex = AddSection("adc");
_TdcSectionIndex = AddSection("tdc");
}
TMyDataAnalyzer::~TMyDataAnalyzer()
{
}
int TMyDataAnalyzer::ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException)
{
const char* SectionName = "unknown";
if (SectionData->SectionIndex() == _AdcSectionIndex) {
SectionName = "adc";
}
else if (SectionData->SectionIndex() == _TdcSectionIndex) {
SectionName = "tdc";
}
// string SectionName = SectionData->SectionName();
int Address, Data;
while (SectionData->GetNext(Address, Data)) {
cout << SectionName << " " << Address << " " << Data << endl;
}
return 1;
}
int TMyDataAnalyzer::ProcessTrailer(int TrailerValue) throw(TKinokoException)
{
if (TrailerValue == TKinokoDataStreamScanner::Trailer_Event) {
cout << endl;
}
return 1;
}
main() および Makefile は,前回の例と同様です.
CamacAdcTdc.kts で取ったデータに対してこのプログラムを実行すると,以下のようになります.
% ./DataAnalyzer02 test02.kdf
adc 0 1234
adc 1 761
adc 2 1650
adc 3 1236
tdc 0 3055
tdc 1 2541
tdc 2 1737
tdc 3 2181
adc 0 1060
adc 1 1200
adc 2 1508
adc 3 1339
tdc 0 1014
tdc 1 2807
tdc 2 2037
tdc 3 2101
adc 0 1339
(以下省略)
%
ストレージヘッダを読む
ストレージヘッダの情報は,main() 関数中で作成した TKinokoKdfReader クラスのインスタンス KdfReader を使って以下のように取得できます.
TKinokoKdfReader* KdfReader = new TKinokoKdfReader(DataFileName);
TKinokoDataAnalyzer* Analyzer = new TMyDataAnalyzer();
KdfReader->RegisterAnalyzer(DataSourceName, Analyzer);
string DateTime = KdfReader->StorageHeader()->ValueOf("DateTime");
cout << "DateTime: " << DateTime << endl;
StorageHeader() メソッドの呼び出しは,全ての RegisterAnalyzer() 呼び出しが終ってから行なうようにしてください.これは Kinoko の内部構造に起因する制約です.
TKinokoKdfReader の StorageHeader() メソッドは,TKinokoStorageHeader クラスのインスタンスへのポインタを返します.TKinokoStorageHeader クラスには,各エントリの情報を取得するための以下のメソッドが定義されています.
TKinokoStorageHeader
- unsigned NumberOfEntries(void) const;
- ストレージヘッダに記録されているエントリの数を返す.
- std::string EntryNameAt(unsigned Index) const;
- Index 番目のエントリのエントリ名を返す.
- std::string ValueAt(unsigned Index) const;
- Index 番目のエントリの値を返す.
- std::string ValueOf(const std::string& Name) const;
- Name に指定されたエントリ名のエントリの値を返す.エントリが存在しない場合は空文字列を返す.
データソースアトリビュートを読む
データソースアトリビュートの情報は,main() 関数中で作成した TKinokoKdfReader クラスのインスタンス KdfReader を使って,以下のように取得できます.
TKinokoKdfReader* KdfReader = new TKinokoKdfReader(DataFileName);
TKinokoDataAnalyzer* Analyzer = new TMyDataAnalyzer();
KdfReader->RegisterAnalyzer(DataSourceName, Analyzer);
TKinokoDataSource* DataSource = KdfReader->DataDescriptor()->DataSource(DataSourceName);
if (DataSource != 0) {
string Fingerprint = DataSource->GetAttributeOf("script_file_fingerprint");
cout << "ScriptFileFingerprint: " << Fingerprint << endl;
}
DataDescriptor() メソッドの呼び出しは,全ての RegisterAnalyzer() 呼び出しが終ってから行なうようにしてください.これは Kinoko の内部構造に起因する制約です.
tagged section のデータを読む
今までの例のデータは全て indexed 型でした.ここでは,DataRecord や taggedRead() などで生成される tagged 型のデータを読みます.
tagged セクションでも,データの読み方には indexed と大きな違いはありません.唯一の違いは,ProcessData() 中の GetNext() で,GetNext(int& Address, int& Data) の代わりに GetNext(string& FieldName, int& Data) を使うことだけです.
static const char* SectionName = "adc";
int TMyDataAnalyzer::ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException)
{
string SectionName = SectionData->SectionName();
string FieldName;
int Data;
while (SectionData->GetNext(FieldName, Data)) {
cout << SectionName << FieldName << " " << Data << endl;
}
return 1;
}
データブロックを読む
次に,block section のデータのように要素(データエレメント)に分けられないデータを読む場合や,indexed や tagged でもデータエレメントに分けずにまとめて読みたい場合に使える,データブロックの読み方を説明します.
ここでも,違いはやはり ProcessData() の中身だけです.セクションデータオブジェクトからデータ領域のポインタを取得するには,GetDataBlock() メソッドを用います.また,データブロックのサイズは,DataBlockSize() メソッドで取得できます.
以下は,データブロックを読んで,それを画面に16進ダンプする例です.
int TMyDataAnalyzer::ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException)
{
void* DataBlock = SectionData->GetDataBlock();
size_t DataBlockSize = SectionData->DataBlockSize();
cout << "[" << SectionData->SectionName() << "]";
cout << hex << setfill('0');
for (unsigned Offset = 0; Offset < DataBlockSize; Offset++) {
if (Offset % 16 == 0) {
cout << endl;
cout << setw(4) << Offset << ": ";
}
else if (Offset % 8 == 0) {
cout << " ";
}
cout << setw(2) << (int) ((unsigned char*) DataBlock)[Offset] << " ";
}
cout << dec << setfill(' ') << endl;
return 1;
}
CamacAdc.kts で取ったデータに対してこのプログラムを実行すると,結果は以下のようになります,
% ./DataAnalyzer03 test03.kdf
[adc]
0000: 00 00 00 00 d2 04 00 00 01 00 00 00 f9 02 00 00
0010: 02 00 00 00 72 06 00 00 03 00 00 00 d4 04 00 00
[adc]
0000: 00 00 00 00 24 04 00 00 01 00 00 00 b0 04 00 00
0010: 02 00 00 00 e4 05 00 00 03 00 00 00 3b 05 00 00
[adc]
0000: 00 00 00 00 3b 05 00 00 01 00 00 00 1d 07 00 00
0010: 02 00 00 00 35 05 00 00 03 00 00 00 9d 06 00 00
(以下省略)
nested section のデータを読む
最後に,unit 文などで生成される nested セクションの読み方を説明します.といっても,プログラム自体には,今までのものとほとんど違いはありません.違いは,セクション名が nested のセクション名に対応したものになるだけです.
例として,以下の読み出しスクリプトで読んだデータを考えます.
on trigger(adc) {
unit event {
adc.read(#0..#3);
tdc.read(#0..#3);
}
}
このスクリプトで読んだデータは以下のようになっています.
% kdfdump test04.kdf -
# Creator: tinykinoko
# DateTime: 2003-03-09 21:57:05 JST
# UserName: sanshiro
# Host: kinoko.awa.tohoku.ac.jp
# Directory: /home/sanshiro/work/kinoko/local/samples
# ScriptFile: CamacAdcTdc.kts
event:adc 0 1736
event:adc 1 1492
event:adc 2 1676
event:adc 3 1086
event:tdc 0 2758
event:tdc 1 2408
event:tdc 2 1877
event:tdc 3 1682
(以下省略)
% kdfcheck test04.kdf
% Preamble Version: 00010002
% Header Version: 00010001
% Data Area Version: 00010001
% Data Format Flags: 00000000
# Creator: tinykinoko
# DateTime: 2003-03-09 21:57:05 JST
# UserName: sanshiro
# Host: kinoko.awa.tohoku.ac.jp
# Directory: /home/sanshiro/work/kinoko/local/samples
# ScriptFile: CamacAdcTdc.kts
[2403]--- 0, 436 bytes
Data Descriptor
datasource "CamacAdcTdc"<2403>
{
attribute creator = "tinykinoko";
attribute creation_date = "2003-03-09 21:57:05 JST";
attribute script_file = "CamacAdcTdc.kts";
attribute script_file_fingerprint = "a3ca80e0";
section "event"<256>: nested {
section "adc"<256>: indexed(address: int-32bit, data: int-32bit);
section "tdc"<257>: indexed(address: int-32bit, data: int-32bit);
}
}
(以下省略)
すなわち,indexed 型のセクション adc, tdc が nested 型のセクション event の中に入っています.
このデータを読むのに必要な変更は,単にセクション名を nested の構造に対応させるだけです.
TMyDataAnalyzer::TMyDataAnalyzer(void)
{
_AdcSectionIndex = AddSection("event:adc");
_TdcSectionIndex = AddSection("event:tdc");
}
プル型データアナライザ
いままでのプログラムは,ProcessData() がフレームワーク側から呼ばれるタイプ(プッシュ型)のアナライザでした.状況によっては,データを読むループをユーザプログラム側で持ち,その中でデータを読み出す(プル型)ようにした方が便利な場合もあります.ここではそのための方法について簡単に考えてみます.
TKinokoKdfReader::Start() を呼び出すと,制御はフレームワークに渡ってしまい,全てのデータを処理し終わるまで返ってきません.TKinokoKdfReader::ProcessNext() は,TKinokoKdfReader::Start() と基本的に同じ処理をしますが,1パケットの処理が終るごとにリターンするので,これを使うことにより,データに対するループをユーザプログラムの中に書くことができます.実際,以下のように,TKinokoKdfReader::ProcessNext() で空のループを組めば,その処理は TKinokoKdfReader::Start() と同等になります(処理スピードは少し変わります).
while (KdfReader->ProcessNext()) {
;
}
ただし,一回の ProcessNext() の呼び出しごとにアナライザの ProcessData() が呼ばれるわけではないことに注意してください.ProcessNext() は1パケット分を処理しますが,パケットにはデータ以外のものや,他のデータソースや他のデータセクションのデータなどもあるからです.
これを使って,データパケットのループをユーザプログラム側に持ってきた例を以下に示します.
#include <cstdlib>
#include <iostream>
#include <string>
#include "KinokoKdfReader.hh"
#include "KinokoSectionDataAnalyzer.hh"
using namespace std;
static const char* DataSourceName = "";
static const char* SectionName = "adc";
static const int NumberOfDataElements = 4;
class TMyDataAnalyzer: public TKinokoSectionDataAnalyzer {
public:
TMyDataAnalyzer(TKinokoKdfReader* KdfReader);
virtual ~TMyDataAnalyzer();
virtual int ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException);
virtual bool GetData(const int*& Data);
protected:
TKinokoKdfReader* _KdfReader;
int _DataBuffer[NumberOfDataElements];
bool _IsDataAvailable;
};
TMyDataAnalyzer::TMyDataAnalyzer(TKinokoKdfReader* KdfReader)
: TKinokoSectionDataAnalyzer(SectionName)
{
_KdfReader = KdfReader;
_IsDataAvailable = false;
}
TMyDataAnalyzer::~TMyDataAnalyzer()
{
}
int TMyDataAnalyzer::ProcessData(TKinokoSectionData* SectionData) throw(TKinokoException)
{
int Address, Data;
while (SectionData->GetNext(Address, Data)) {
if (Address < NumberOfDataElements) {
_DataBuffer[Address] = Data;
}
}
_IsDataAvailable = true;
return 1;
}
bool TMyDataAnalyzer::GetData(const int*& Data)
{
while (! _IsDataAvailable) {
if (! _KdfReader->ProcessNext()) {
return false;
}
}
Data = _DataBuffer;
_IsDataAvailable = false;
return true;
}
int main(int argc, char** argv)
{
if (argc < 2) {
cerr << "Usage: " << argv[0] << " DataFileName" << endl;
return EXIT_FAILURE;
}
string DataFileName = argv[1];
TKinokoKdfReader* KdfReader = new TKinokoKdfReader(DataFileName);
TMyDataAnalyzer* Analyzer = new TMyDataAnalyzer(KdfReader);
try {
KdfReader->RegisterAnalyzer(DataSourceName, Analyzer);
const int* Data;
while (Analyzer->GetData(Data)) {
for (int i = 0; i < NumberOfDataElements; i++) {
cout << i << " " << Data[i] << endl;
}
cout << endl;
}
}
catch (TKinokoException& e) {
cerr << "ERROR: " << e << endl;
return EXIT_FAILURE;
}
delete Analyzer;
delete KdfReader;
return 0;
}
データファイルの読み方 2 - DataProcessor を使う -
KinokoSectionDataAnalyzer を使ってデータファイルを読むのは,手軽ですが,できることには限りがあります.例えば,複数のデータソースからのデータを同時に処理したり,未知のデータソース/データセクションのデータを読むなどという処理は,KinokoDataSectionAnalyzer では多少無理があります.この場合は,もう一つのデータ解析フレームワークである KinokoDataProcessor を使うことになります.
また,DataProcessor を使ったコードは,コンポーネントとしてオンラインストリームに統合することが極めて容易です(もともと DataProcessor はこの目的のために設計されました).将来オンラインにする予定のデータ処理やオンラインとオフラインの両方で使用したいコードなどは,DataProcessor のフレームワークを使うほうが便利です.
DataProcessor はデータパケットの中身を直接ユーザに見せるため,indexed や tagged のデータをこのフレームワークで扱うことは,多少わずらわしい面がありますが,block 型のデータに関してはむしろ簡単になります.
簡単な例
DataProcessor は,オンラインでデータを処理するためのフレームワークとしてはじめに設計されました.そのため,オンラインストリームにおける3つの形態 (Source, Pipe, Sink) に応じて,DataProducer, DataProcessor, DataConsumer の3種類があります.ここでは,データを読むだけなので,DataConsumer を使用します.
以下は,データファイルに含まれる全データパケットの,DataSourceId と SectionId およびデータの 16進ダンプを表示するプログラムです.
#include <iostream>
#include <iomanip>
#include "MushArgumentList.hh"
#include "KinokoDataProcessor.hh"
#include "KinokoStandaloneComponent.hh"
using namespace std;
class TMyDataConsumer: public TKinokoDataConsumer {
public:
TMyDataConsumer(void);
virtual ~TMyDataConsumer();
virtual void OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException);
virtual void OnReceiveTrailerPacket(void* DataPacket, long PacketSize) throw(TKinokoException);
};
TMyDataConsumer::TMyDataConsumer(void)
{
}
TMyDataConsumer::~TMyDataConsumer()
{
}
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
void* Data = TKinokoDataSectionScanner::DataAreaOf(DataPacket);
size_t DataSize = TKinokoDataSectionScanner::DataSizeOf(DataPacket);
cout << "[" << DataSourceId << ":" << SectionId << "]";
cout << hex << setfill('0');
for (unsigned Offset = 0; Offset < DataSize; Offset++) {
if (Offset % 16 == 0) {
cout << endl;
cout << setw(4) << Offset << ": ";
}
else if (Offset % 8 == 0) {
cout << " ";
}
cout << setw(2) << (int) ((unsigned char*) Data)[Offset] << " ";
}
cout << dec << setfill(' ') << endl;
}
void TMyDataConsumer::OnReceiveTrailerPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
int TrailerValue = TKinokoDataStreamScanner::TrailerValueOf(DataPacket);
cout << "[" << DataSourceId << ":" << TrailerValue << "]" << endl;
cout << endl;
}
int main(int argc, char** argv)
{
TMushArgumentList ArgumentList(argc, argv);
TMyDataConsumer MyDataConsumer;
TKinokoStandaloneDataConsumer StandaloneDataConsumer(&MyDataConsumer, "MyDataConsumer");
try {
StandaloneDataConsumer.Start(ArgumentList);
}
catch (TKinokoException &e) {
cerr << "ERROR: " << e << endl;
}
return 0;
}
まず,KinokoDataConsumer を継承して,MyDataConsumer をつくり,OnReceiveDataPacket() をオーバーライドします.OnReceiveDataPacket() は,データパケットを受け取るたびに呼び出されるメソッドです.引数には,データパケット自体へのポインタと,データパケットのサイズが渡されます.
データパケットから DataSourceId を得るには,TKinokoDataStreamScanner の静的メソッド DataSourceIdOf() を用います.同様に,SectionId は,TKinokoDataSectionScanner の SectionIdOf() を使います.
TKinokoDataSectionScanner を使うと,パケット中のデータブロックへのポインタと,データブロックのサイズも取得することができます.
main() 関数で TMyDataConsumer のインスタンス MyDataConsumer を作成し,TKinokoStandaloneDataConsumer を使ってシステムと結びつけます.ここで,TKinokoStandaloneDataConsumer の代わりに TKinokoDataConsumerCom を使うと,そのままオンライン用のデータ解析コンポーネントとなります.TKinokoStandaloneDataConsumer にプログラム引数 (ArgumentList) を渡して Start() を呼べば,あとは全て Kinoko が処理をおこないます.
このプログラムのコンパイル手順は,データアナライザを使用する場合と基本的に同じです.
# Makefile for sample DataProcessor
CXX = $(shell kinoko-config --cxx)
FLAGS = $(shell kinoko-config --flags)
LIBS = $(shell kinoko-config --libs)
DataProcessor01: DataProcessor.o
$(CXX) -o $@ $@.o $(LIBS)
.cc.o:
$(CXX) $(FLAGS) -c $<
データデスクリプタを読む
DataProcessor は,データパケットをそのままの形で渡すので,その解釈には通常データデスクリプタが必要です(DataSourceId や SectionId が読み出しスクリプト等で固定されている場合は,この手順は省くことができます).
TMyDataConsumer を作った際の親クラス TKinokoDataConsumer は,データデスクリプタオブジェクト _InputDataDescriptor を持っており,ここからデータデスクリプタの情報を得ることができます.また,TKinokoDataConsumer は,最初の RunBegin パケットを受け取ったときにメソッド OnRunBegin() を呼ぶので,これを継承してこの中でデータデスクリプタを処理することにします.
クラス定義は以下のようになります.メソッド OnRunBegin() を追加し,メンバで処理対象のデータソース・セクションの名前とIDを保持するようにします.
#include "KinokoDataSource.hh"
#include "KinokoDataSection.hh"
class TMyDataConsumer: public TKinokoDataConsumer {
public:
TMyDataConsumer(string DataSourceName, string SectionName);
virtual ~TMyDataConsumer();
virtual void OnRunBegin(void) throw(TKinokoException);
virtual void OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException);
protected:
string _DataSourceName, _SectionName;
int _DataSourceId, _SectionId;
};
コンストラクタで処理対象のデータソース・セクションの名前を受け取ります.DataSouceId と SectionId は無効を示す負の値を入れておきます.
TMyDataConsumer::TMyDataConsumer(string DataSourceName, string SectionName)
{
_DataSourceName = DataSourceName;
_SectionName = SectionName;
_DataSourceId = -1;
_SectionId = -1;
}
OnRunBegin() メソッドでは,親クラスである TKinokoDataConsumer が保持している _DataDescriptor オブジェクトから DataSource オブジェクトを,DataSouce オブジェクトから DataSection オブジェクトを順に取得し,それぞれの ID を得ます.
void TMyDataConsumer::OnRunBegin(void) throw(TKinokoException)
{
TKinokoDataSource* DataSource = _InputDataDescriptor->DataSource(_DataSourceName);
if (DataSource != 0) {
_DataSourceId = DataSource->DataSourceId();
TKinokoDataSection* DataSection = DataSource->DataSection(_SectionName);
if (DataSection != 0) {
_SectionId = DataSection->SectionId();
}
}
}
OnReceiveDataPacket() では,受け取ったデータパケットの DataSourceId/SectionId を保持している処理対象の DataSouceId/SectionId と比較し,処理対象でない場合はスキップするようにします.
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
if (DataSourceId != _DataSourceId) {
return;
}
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
if (SectionId != _SectionId) {
return;
}
(以下省略)
main() 関数では,MyDataConsumer に処理対象のデータソースおよびデータセクションの名前を渡すようにします.
int main(int argc, char** argv)
{
TMyDataConsumer MyDataConsumer("CamacAdc", "adc");
(以下省略)
TKinokoDataDescriptor は,データデスクリプタに書かれた全ての情報を保持しているオブジェクトです.基本的に各データソースの情報を保持する TKinokoDataSource のリストです.TKinokoDataSource は,さらに各セクションの情報を保持する TKinokoDataSection を保持しています.以下は,これらのクラスで利用できるメソッドのリストです.
TKinokoDataDescriptor
- TKinokoDataSource* DataSource(long DataSourceId)
- データソースIDから,データソースオブジェクトを検索し,見つかればそれを返す.見つからない場合は 0 を返す.
- TKinokoDataSource* DataSource(const std::string& DataSourceName)
- データソース名から,データソースオブジェクトを検索し,見つかればそれを返す.見つからない場合は 0 を返す.
- const std::vector<TKinokoDataSource*>& DataSourceList(void)
- 保持している全てのデータソースオブジェクトのリストを返す.
TKinokoDataSource
- long DataSourceId(void) const
- データソースIDを返す.
- const std::string& DataSourceName(void) const
- データソース名を返す.
- TKinokoDataSection* DataSection(int SectionId)
- セクションIDから,データセクションオブジェクトを検索し,見つかればそれを返す.見つからない場合は 0 を返す.
- TKinokoDataSection* DataSection(const std::string& SectionName)
- セクション名から,データセクションオブジェクトを検索し,見つかればそれを返す.見つからない場合は 0 を返す.
- bool GetAttributeOf(const std::string& Name, std::string& Value)
- データソースアトリビュートを取得し,Value に入れる.アトリビュートが見つかれば true を,見つからなければ false を返す.
TKinokoDataSection
- int SectionType(void) const
- セクション型に対応する値を返す.以下の enum 値が定義されている.
- TKinokoDataSection::SectionType_Indexed
- TKinokoDataSection::SectionType_Tagged
- TKinokoDataSection::SectionType_Block
- TKinokoDataSection::SectionType_Nested
- int SectionId(void) const
- セクションIDを返す.
- const std::string& SectionName(void) const
- セクション名を返す.
- TKinokoDataSource* DataSource(void) const
- このセクションが属するデータソースのデータソースオブジェクトを返す.
indexed 型のデータを読む
indexed 型のデータを読むためには,データブロックの中身を解読する必要があります.データブロック内のフォーマットをカプセル化し,データブロックからデータエレメントを取り出すインターフェースを提供するものとして,TKinokoIndexedDataSectionScanner クラスがあります.あるセクションデータを読むためのスキャナオブジェクトは,対応するデータセクションオブジェクトにより生成されます.
以下の例では,OnRunBegin() 内でスキャナオブジェクトも取得し,それを OnReceiveDataPacket() で使っています.スキャナオブジェクトは,生成したデータセクションオブジェクトにより削除されるので,ユーザがこれを削除する必要はありません.
#include "KinokoIndexedDataSection.hh"
class TMyDataConsumer: public TKinokoDataConsumer {
public:
TMyDataConsumer(string DataSourceName, string SectionName);
virtual ~TMyDataConsumer();
virtual void OnRunBegin(void) throw(TKinokoException);
virtual void OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException);
protected:
string _DataSourceName, _SectionName;
int _DataSourceId, _SectionId;
TKinokoIndexedDataSectionScanner* _Scanner;
};
void TMyDataConsumer::OnRunBegin(void) throw(TKinokoException)
{
TKinokoDataSource* DataSource = _InputDataDescriptor->DataSource(_DataSourceName);
if (DataSource != 0) {
_DataSourceId = DataSource->DataSourceId();
TKinokoDataSection* DataSection = DataSource->DataSection(_SectionName);
if (DataSection != 0) {
_SectionId = DataSection->SectionId();
if (DataSection->SectionType() != TKinokoDataSection::SectionType_Indexed) {
throw TKinokoException("invalid section type");
}
_Scanner = ((TKinokoIndexedDataSection*) DataSection)->Scanner();
}
}
}
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
if (DataSourceId != _DataSourceId) {
return;
}
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
if (SectionId != _SectionId) {
return;
}
int NumberOfElements = _Scanner->NumberOfElements(DataPacket);
int Address, Data;
for (int Index = 0; Index < NumberOfElements; Index++) {
_Scanner->ReadFrom(DataPacket, Index, Address, Data);
cout << Address << " " << Data << endl;
}
}
tagged 型のデータを読む
tagged 型のセクションを読む場合も,基本的に indexed 型の場合と同様に,Scanner を使用します.ただし,この場合は tagged セクション用の TKinokoTaggedSectionDataScanner になります.
#include "KinokoTaggedDataSection.hh"
class TMyDataConsumer: public TKinokoDataConsumer {
public:
TMyDataConsumer(string DataSourceName, string SectionName);
virtual ~TMyDataConsumer();
virtual void OnRunBegin(void) throw(TKinokoException);
virtual void OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException);
protected:
string _DataSourceName, _SectionName;
int _DataSourceId, _SectionId;
TKinokoTaggedDataSection* _DataSection;
TKinokoTaggedDataSectionScanner* _Scanner;
};
void TMyDataConsumer::OnRunBegin(void) throw(TKinokoException)
{
TKinokoDataSource* DataSource = _InputDataDescriptor->DataSource(_DataSourceName);
if (DataSource != 0) {
_DataSourceId = DataSource->DataSourceId();
TKinokoDataSection* DataSection = DataSource->DataSection(_SectionName);
if (DataSection != 0) {
_SectionId = DataSection->SectionId();
if (DataSection->SectionType() != TKinokoDataSection::SectionType_Tagged) {
throw TKinokoException("invalid section type");
}
_DataSection = (TKinokoTaggedDataSection*) DataSection;
_Scanner = _DataSection->Scanner();
}
}
}
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
if (DataSourceId != _DataSourceId) {
return;
}
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
if (SectionId != _SectionId) {
return;
}
int NumberOfFields = _DataSection->NumberOfFields()
int Data;
for (int Index = 0; Index < NumberOfElements; Index++) {
string FieldName = _DataSection->FieldNameOf(Index);
_Scanner->ReadFrom(DataPacket, Index, Data);
cout << FieldName << " " << Data << endl;
}
}
あらかじめ処理対象のフィールド名が決まっている場合,OnRunBegin() で FieldIndex を取得しておくと処理が速くなります.
void TMyDataConsumer::OnRunBegin(void) throw(TKinokoException)
{
TKinokoDataSource* DataSource = _InputDataDescriptor->DataSource(_DataSourceName);
if (DataSource != 0) {
_DataSourceId = DataSource->DataSourceId();
TKinokoDataSection* DataSection = DataSource->DataSection(_SectionName);
if (DataSection != 0) {
_SectionId = DataSection->SectionId();
if (DataSection->SectionType() != TKinokoDataSection::SectionType_Tagged) {
throw TKinokoException("invalid section type");
}
_DataSection = (TKinokoTaggedDataSection*) DataSection;
_Scanner = _DataSection->Scanner();
_EventNumberIndex = _DataSection->FieldIndexOf("event_number");
_EventTimeIndex = _DataSection->FieldIndexOf("event_time");
}
}
}
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
if (DataSourceId != _DataSourceId) {
return;
}
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
if (SectionId != _SectionId) {
return;
}
int Data;
_Scanner->ReadFrom(DataPacket, _EventNumberIndex, Data);
cout << "event_number: " << Data << endl;
_Scanner->ReadFrom(DataPacket, _EventTimeIndex, Data);
cout << "event_time: " << Data << endl;
}
フィールドの数が増えてインデックスの管理が繁雑になった場合には,データ用変数を直接 Scanner に登録してしまう方法もあります(登録する変数の管理に注意を要します).
void TMyDataConsumer::OnRunBegin(void) throw(TKinokoException)
{
TKinokoDataSource* DataSource = _InputDataDescriptor->DataSource(_DataSourceName);
if (DataSource != 0) {
_DataSourceId = DataSource->DataSourceId();
TKinokoDataSection* DataSection = DataSource->DataSection(_SectionName);
if (DataSection != 0) {
_SectionId = DataSection->SectionId();
if (DataSection->SectionType() != TKinokoDataSection::SectionType_Tagged) {
throw TKinokoException("invalid section type");
}
_DataSection = (TKinokoTaggedDataSection*) DataSection;
_Scanner = _DataSection->Scanner();
_Scanner->MapVariable("event_number", &_EventNumber);
_Scanner->MapVariable("event_time", &_EventTime);
}
}
}
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
if (DataSourceId != _DataSourceId) {
return;
}
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
if (SectionId != _SectionId) {
return;
}
_Scanner->Update(DataPacket);
cout << "event_number: " << _EventNumber << endl;
cout << "event_time: " << _EventTime << endl;
}
TKinokoTaggedDataSetion で利用できるメソッドの一部を以下に示します.
- bool HasField(const std::string& FieldName)
- FieldName の名前を持ったフィールドが存在すれば true を,しなければ false を返す.
- int FieldIndexOf(const std::string& FieldName) throw(TKinokoException)
- FieldName の名前のフィールドのインデクスを返す.フィールドが存在しない場合は例外 TKinokoException を投げる.
- std::string FieldNameOf(int FieldIndex) throw(TKinokoException)
- FieldIndex のインデクスのフィールド名を返す.Index が範囲外の場合は例外 TKinokoException を投げる.
- int NumberOfFields(void)
- フィールドの数を返す.
nested 型のデータを読む
datasource CamacAdc
{
CamacCrate crate;
CamacController controller("Toyo-CC7x00");
CamacModule adc("Rinei-RPC022");
crate.installController(controller);
crate.installModule(adc, 10);
DataRecord event_info;
Register event_number, event_time;
on trigger(timer) {
event_number += 1;
readTime(event_time);
unit event {
adc.read(#0..#3);
adc.clear();
event_info.fill("event_number", event_number);
event_info.fill("event_time", event_time);
event_info.send();
}
}
}
datasource "CamacAdc"<3603>
{
attribute creator = "tinykinoko";
attribute creation_date = "2008-07-19 07:25:07 JST";
attribute script_file = "NestedDataSection.kts";
attribute script_file_fingerprint = "81d9e4ae";
section "event"<257>: nested {
section "adc"<258>: indexed(address: int-32bit, data: int-32bit);
section "event_info"<259>: tagged {
field "event_number": int-32bit;
field "event_time": int-32bit;
}
}
}
#include <iostream>
#include "MushArgumentList.hh"
#include "KinokoDataSource.hh"
#include "KinokoDataSection.hh"
#include "KinokoIndexedDataSection.hh"
#include "KinokoTaggedDataSection.hh"
#include "KinokoNestedDataSection.hh"
#include "KinokoDataProcessor.hh"
#include "KinokoStandaloneComponent.hh"
using namespace std;
class TMyDataConsumer: public TKinokoDataConsumer {
public:
TMyDataConsumer(void);
virtual ~TMyDataConsumer();
virtual void OnRunBegin(void) throw(TKinokoException);
virtual void OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException);
protected:
int _DataSourceId;
int _EventSectionId;
TKinokoNestedDataSection* _EventSection;
TKinokoNestedDataSectionScanner* _EventScanner;
int _EventInfoSectionId;
TKinokoTaggedDataSection* _EventInfoSection;
TKinokoTaggedDataSectionScanner* _EventInfoScanner;
int _AdcSectionId;
TKinokoIndexedDataSection* _AdcSection;
TKinokoIndexedDataSectionScanner* _AdcScanner;
};
TMyDataConsumer::TMyDataConsumer(void)
{
}
TMyDataConsumer::~TMyDataConsumer()
{
}
void TMyDataConsumer::OnRunBegin(void) throw(TKinokoException)
{
string DataSourceName;
string SectionName;
TKinokoDataSource* DataSource;
TKinokoDataSection* DataSection;
DataSourceName = "CamacAdc";
DataSource = _InputDataDescriptor->DataSource(DataSourceName);
if (DataSource == 0) {
throw TKinokoException("datasouce not found: " + DataSourceName);
}
_DataSourceId = DataSource->DataSourceId();
SectionName = "event";
DataSection = DataSource->DataSection(SectionName);
if (DataSection == 0) {
throw TKinokoException("section not found: " + SectionName);
}
_EventSectionId = DataSection->SectionId();
_EventSection = (TKinokoNestedDataSection*) DataSection;
_EventScanner = _EventSection->Scanner();
SectionName = "event_info";
DataSection = _EventSection->DataSection(SectionName);
if (DataSection == 0) {
throw TKinokoException("section not found: " + SectionName);
}
_EventInfoSectionId = DataSection->SectionId();
_EventInfoSection = (TKinokoTaggedDataSection*) DataSection;
_EventInfoScanner = _EventInfoSection->Scanner();
SectionName = "adc";
DataSection = _EventSection->DataSection(SectionName);
if (DataSection == 0) {
throw TKinokoException("section not found: " + SectionName);
}
_AdcSectionId = DataSection->SectionId();
_AdcSection = (TKinokoIndexedDataSection*) DataSection;
_AdcScanner = _AdcSection->Scanner();
}
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
if (DataSourceId != _DataSourceId) {
cout << "### Unexpected DataSource: ID=" << DataSourceId << endl;
return;
}
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
if (SectionId != _EventSectionId) {
cout << "### Unexpected DataSection: ID=" << SectionId << endl;
return;
}
int DataSize = _EventScanner->DataSizeOf(DataPacket);
U8bit* SubPacket = (U8bit*) _EventScanner->DataAreaOf(DataPacket);
int SubPacketSize;
int ProcessedSize = 0;
while (ProcessedSize < DataSize) {
int SectionId = TKinokoDataSectionScanner::SectionIdOf(SubPacket);
if (SectionId == _EventInfoSectionId) {
int NumberOfFields = _EventInfoSection->NumberOfFields();
int Data;
for (int Index = 0; Index < NumberOfFields; Index++) {
string FieldName = _EventInfoSection->FieldNameOf(Index);
_EventInfoScanner->ReadFrom(DataPacket, Index, Data);
cout << FieldName << " " << Data << endl;
}
}
else if (SectionId == _AdcSectionId) {
int NumberOfElements = _AdcScanner->NumberOfElements(DataPacket);
int Address, Data;
for (int Index = 0; Index < NumberOfElements; Index++) {
_AdcScanner->ReadFrom(DataPacket, Index, Address, Data);
cout << Address << " " << Data << endl;
}
}
else {
cout << "### Unexpected DataSection: ID=" << SectionId << endl;
}
SubPacketSize = TKinokoDataSectionScanner::PacketSizeOf(SubPacket);
ProcessedSize += SubPacketSize;
SubPacket += SubPacketSize;
}
}
int main(int argc, char** argv)
{
TMushArgumentList ArgumentList(argc, argv);
TMyDataConsumer MyDataConsumer;
TKinokoStandaloneDataConsumer StandaloneDataConsumer(&MyDataConsumer, "MyDataConsumer");
try {
StandaloneDataConsumer.Start(ArgumentList);
}
catch (TKinokoException &e) {
cerr << "ERROR: " << e << endl;
}
return 0;
}
データストリームの読み方 - DataProcessor をコンポーネントにする -
前章で説明した DataProcessor を使ってデータをファイルから読むプログラムが作成できていれば,これを実行中の Kinoko のデータストリームに接続して動作するコンポーネントにするのは極めて容易です.このために必要な変更は,main() の中の TKinokoStandaloneDataConsumer を TKinokoDataConsumerCom に変更し,TKcomProcess のインスタンスをひとつ作成してこれに渡すだけです.コンポーネントのデバッグは煩わしいことが多いので,このように一度スタンドアロンのプログラムを作成しテストしてからコンポーネント化するのが楽です.
以下は,前章の例 DataProcessor01 をコンポーネント化したものです.
行った変更は,インクルードファイルの追加を除き,わずか3行です.
#include <iostream>
#include <iomanip>
#include "MushArgumentList.hh"
#include "KinokoDataProcessor.hh"
#include "KinokoDataProcessorCom.hh"
#include "KcomProcess.hh"
using namespace std;
class TMyDataConsumer: public TKinokoDataConsumer {
public:
TMyDataConsumer(void);
virtual ~TMyDataConsumer();
virtual void OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException);
};
TMyDataConsumer::TMyDataConsumer(void)
{
}
TMyDataConsumer::~TMyDataConsumer()
{
}
void TMyDataConsumer::OnReceiveDataPacket(void* DataPacket, long PacketSize) throw(TKinokoException)
{
int DataSourceId = TKinokoDataStreamScanner::DataSourceIdOf(DataPacket);
int SectionId = TKinokoDataSectionScanner::SectionIdOf(DataPacket);
void* Data = TKinokoDataSectionScanner::DataAreaOf(DataPacket);
size_t DataSize = TKinokoDataSectionScanner::DataSizeOf(DataPacket);
cout << "[" << DataSourceId << ":" << SectionId << "]";
cout << hex << setfill('0');
for (unsigned Offset = 0; Offset < DataSize; Offset++) {
if (Offset % 16 == 0) {
cout << endl;
cout << setw(4) << Offset << ": ";
}
else if (Offset % 8 == 0) {
cout << " ";
}
cout << setw(2) << (int) ((unsigned char*) Data)[Offset] << " ";
}
cout << dec << setfill(' ') << endl;
}
int main(int argc, char** argv)
{
TMushArgumentList ArgumentList(argc, argv);
TMyDataConsumer MyDataConsumer;
TKinokoDataConsumerCom DataConsumerCom(&MyDataConsumer);
TKcomProcess ComProcess(&DataConsumerCom);
try {
ComProcess.Start(ArgumentList);
}
catch (TKinokoException &e) {
cerr << "ERROR: " << e << endl;
}
return 0;
}
KCOM の規約により,ファイル名は [コンポーネント名-kcom] でなければなりません.
作成したコンポーネントのインターフェース宣言は以下のようになります.
% ./MyDataProcessor-kcom
//
// KinokoDataConsumerCom.kidl
//
// Kinoko Data-Stream Component
// DataConsumer: User Data Process Component
component KinokoDataConsumerCom {
property string component_type;
property string host;
property long condition_check_time;
property long heart_beat_rate;
property long vital_level;
property string stream_type;
property string state;
property int port_number;
uses KinokoLogger logger;
accepts system();
accepts enableConditionMonitor();
accepts setSource();
accepts setSink();
accepts setSourceSink();
accepts connect();
accepts construct();
accepts destruct();
accepts disconnect();
accepts halt();
accepts quit();
}
このコンポーネントをシステムに組込みデータストリームに接続するには,[SmallKinoko の構造と拡張] で説明している方法で KCOM スクリプトを編集します.他のデータストリームコンポーネント同様,setSource() で接続元を指定してから connect() し,construct() をします.終了時には destruct() してから disconnect() し,quit() をします.
SmallKinoko.kcom を編集して MyDataProcessor を接続した例が kinoko/tutorial/DataAnalyzer/MyDataProcessor.kcom にあるので参考にしてください.SmallKinoko.kcom からの変更はわずか8行の追加です(viewer の後ろに同名のメソッドを加えているだけ).SmallKinoko.kcom との diff をとると必要な変更を一覧できます.
% diff $KINOKO_ROOT/scripts/SmallKinoko.kcom MyDataProcessor.kcom
14a15
> import MyDataProcessor;
117a119
> component MyDataProcessor my_processor(host);
320a323
> my_processor.setSource(buffer);
327a331
> my_processor.connect();
416a421
> my_processor.construct();
470a476
> my_processor.destruct();
493a500
> my_processor.disconnect();
505a513
> my_processor.quit();
[SmallKinoko の構造と拡張] で説明しているように,KCOM スクリプトは kinoko コマンドで実行します.コンポーネント実行ファイルを Kinoko 標準でない場所に置く場合は,環境変数 KCOM_PATH でその場所を指定してください.コロン区切りで複数のパスを指定できます.
% echo $KCOM_PATH
.:/home/kinoko/kinoko/bin
% kinoko MyDataProcessor.kcom
この例では,データストリームから受け取ったデータを単純に標準出力に書き出しているだけですが,これをデータストレージに書き出したり描画ツールに渡したりすることにより様々な応用ができます.受け取ったデータを加工して Kinoko に戻す方法は拡張方法の章で説明します.
Edited by: Enomoto Sanshiro
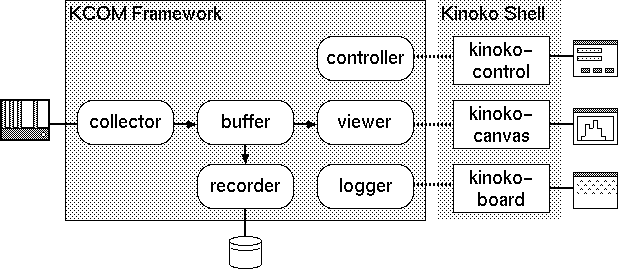
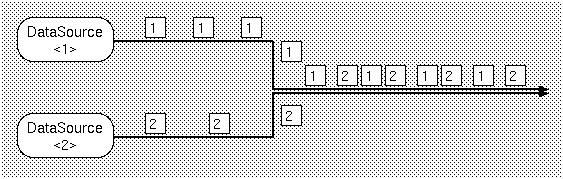
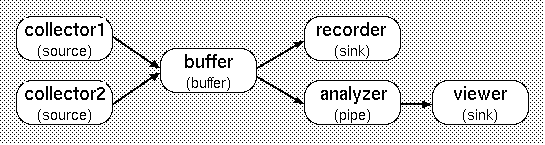
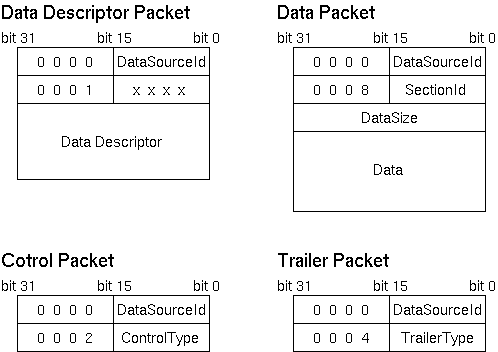
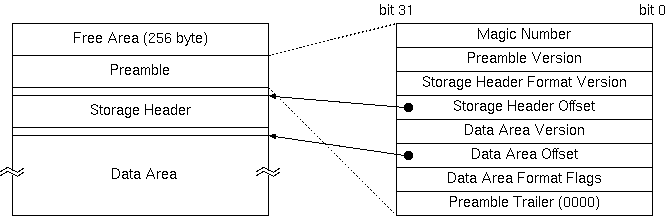
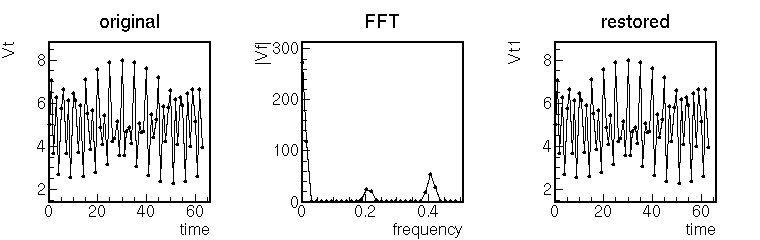
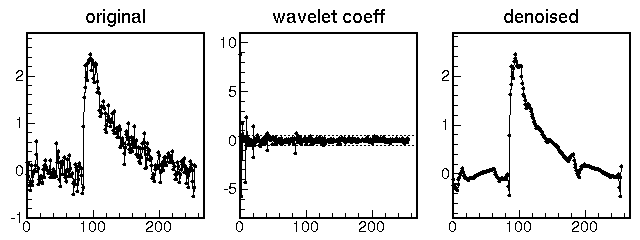
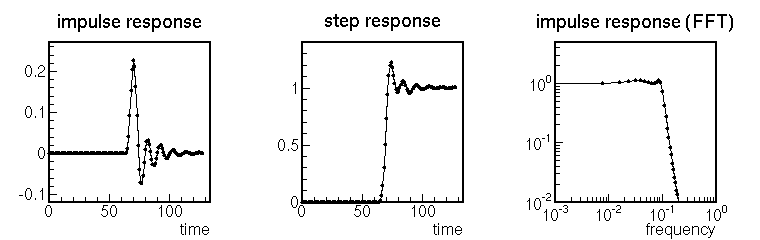
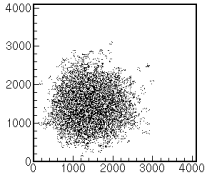
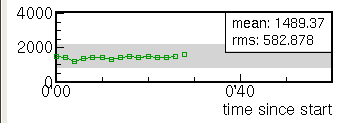
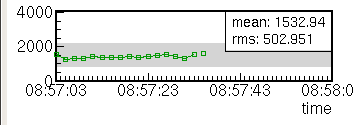
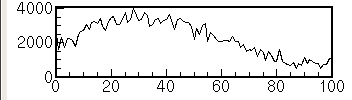
 スクリーンショット(大) (PNG 25kB)
スクリーンショット(大) (PNG 25kB)

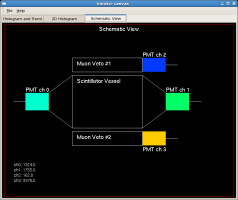 スクリーンショット(大) (PNG 15kB)
スクリーンショット(大) (PNG 15kB)